Attention Is All You Need
“AI時代の生き方に、音楽は様々なヒントを与えてくれるかもしれない”
このBlogの副題ですが、それゆえAI を取り巻く話題についてこれまでも取り上げてきました。
https://beflat.iiv.jp/xml773
https://beflat.iiv.jp/xml714
ChatGPTをはじめとする生成AIについて、今回はその仕組みについて掘り下げてみました。
(仕組みをわかりやすく説明するものでなく、私が学習した備忘録のようになっています。)
タイトルは下記論文のものです。
https://arxiv.org/pdf/1706.03762.pdf
まずは用語の説明です。
GPT:Generative Pre-trained Transformer
Chat GPT :OpenAIが開発した、大規模言語モデル(LLM:Large Language Model)であるGPTを使ったチャットサービス
Transformer :従来から使用されてきたCNN やRNN と違い Attensionと呼ばれる仕組みに基づいたエンコーダデコーダモデル
CNN:Convolutional neural network 畳み込みニューラルネットワークといい画像や動画認識に広く使われているモデル
RNN;Recurrent Neural Network 再帰型ニューラルネットワークといい時系列データ(株価や気温の推移等)の扱いに最適
参考動画
【Transformerの基礎】Multi-Head Attentionの仕組み
https://www.youtube.com/watch?v=XOekdMBhMxU&t=166s
もともとは言語翻訳の分野で研究され、学習するときにどこに注目するか(どのデータに注意するか)といった情報が付加されることによって従来のLSTMなどによる方法より高い性能を上げられるようになりました。
これがTransformerというモデルです。ChatGPTはPre-trained(学習済み)ですので、デコーダのみを使います。
構造について論文から引用
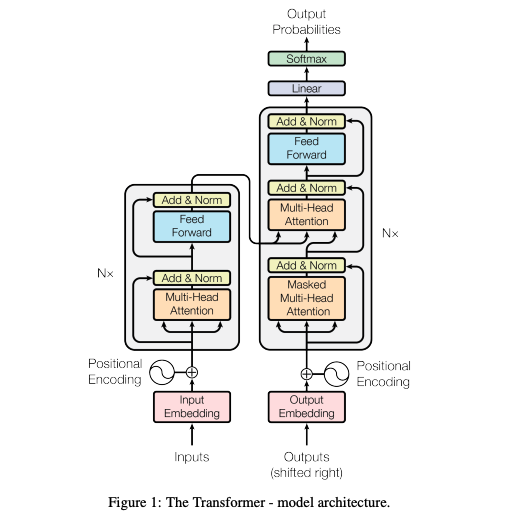
LSTM :(Long Short-Term Memory: 長・短期記憶) ネットワークは、RNN(再帰型 ニューラル ネットワーク) の一種
LSTM の強みは、時系列データの学習や予測(回帰・分類)にあります。
一般的な応用分野としては感情分析、言語モデリング、音声認識、動画解析などがあります。 (https://jp.mathworks.com/discovery/lstm.html より)
Scaled Dot-Product Attention、Multi-Head Attention、QKV
構造について論文から引用
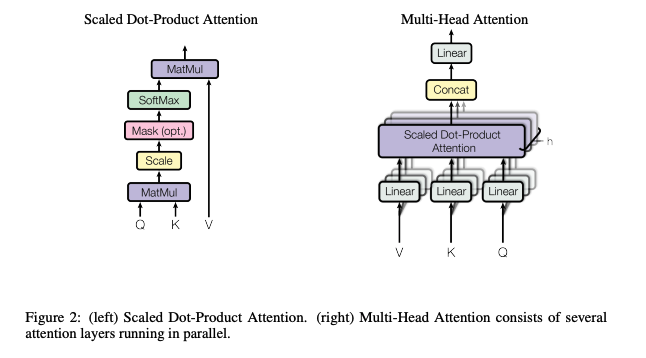
マルチヘッドアテンションについて
https://cvml-expertguide.net/terms/dl/seq2seq-translation/transformer
“Transformerの設計は,マルチヘッドアテンションを主要ブロックとして採用したのが,最大の特徴である.マルチヘッドアテンションは「系列内自己アテンション or 系列間相互アテンション」アテンションの役割を担当する”
参考動画
https://www.youtube.com/watch?v=g5DSLeJozdw&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ
画像のセルフ(自己)アテンションを例にわかりやすく説明されている。
Query ,Key,Valueの違いについて
https://www.youtube.com/watch?v=50XvMaWhiTY&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ
V=K=Q=入力X だが これに行列をかけて回してあげる、Q ,Kそれぞれ回転させてから内積をとる、Vも回して出力調整
様々な角度からXの横ベクトルを比較して、どこに注目するかを制御して出力を決定するのが、Multi-Head Attension.
ChatGPTの仕組み
参考動画
https://www.youtube.com/watch?v=om-PZpvnCBM&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ&index=13&t=132s
仕組みについて理解するのは難しいですが、誤解を恐れずに言うならば、従来のLSTMでなく、TransformerのモデルがたまたまうまくいったためChatGPTのようなものが生まれた、と言えるかもしれません。(必要なのはアテンションだけ。構造に能力が宿るのだろうか・・これがすごく気になります)
ニューラルネットワーク自体、人間の脳の仕組みを模倣したものをコンピュータ上に実装しています。これを使うと画像認識など、データから答えを求めることができてしまいますが、なぜその答えが出たのか、そのプロセスの説明は困難です。Transformerも同じように考えられます。この先、意識は? 感情は? といったもの(モデル?)についても研究が進むのでしょう。 (偶然、感情に適したモデル(構造)ができちゃった、なんてことがあるかも・・)
さて、ここからが本題ですが、楽器などを練習していて思うのが、これってリアルディープラーニングかも、と思うことがあります。(もちろん人間が本家なのでおかしな言い方ですが)
同じフレーズを繰り返し演奏して、少しずつ上達する様子が、AI による学習に似ていると思うことありませんか?(音楽は時系列なのでRNNか)
特に、上記のセルフアテンションの仕組みを知った時、これはドラムプレイに当てはまっているのでは、と思いました。
ドラムセットをプレイするのを見て、よく手足がバラバラに動いていると思われる方は多いです。しかし実際には右手と右足、左手と左足は連動して動いていたりすることがあり、右足に注目して、右手の動きをする場合や、左足をタイムキープの軸にしたるすることがあります。
つまりどこかに注目(アテンション)するわけですが、これを変えると全く別の体の動きとなり、また新たに違うパターンとして練習をし直す必要があることがあるます。
ドラマーにしかわからないかもしれませんが、簡単な8ビートのパターンを叩いている時に、左足を4分で軽く踏んでいるとします。このとき左足を4分の裏で踏むように変えると、一気に叩けているはずの右手、右足、左手がぎこちない動きになります。(Positinal Encodingが影響するか)
筋肉の動きには問題がなくても、神経の働きが学習されていないせいなのではと思っています。
下記投稿の動画のイントロ部分もそうなのですが、Swingということで左足を裏拍で踏んだら一気に難しくなってしまいました。
https://beflat.iiv.jp/xml784
まあ飛躍的な考え方と思われかもしれませんが、脳が手足にどのように指示を出しているのか(先読み、条件反射、・・)、個人的にはとても興味深いテーマです。
AI研究が進む中、音楽が果たす役割は大きいと思います。
先ほどの、意識、感情、に続いて、創造力にもモデルがあるのだろうか。
 D5 Creation
D5 Creation
Comments are Closed