投稿者: Kei
Two Click Flare Scratch
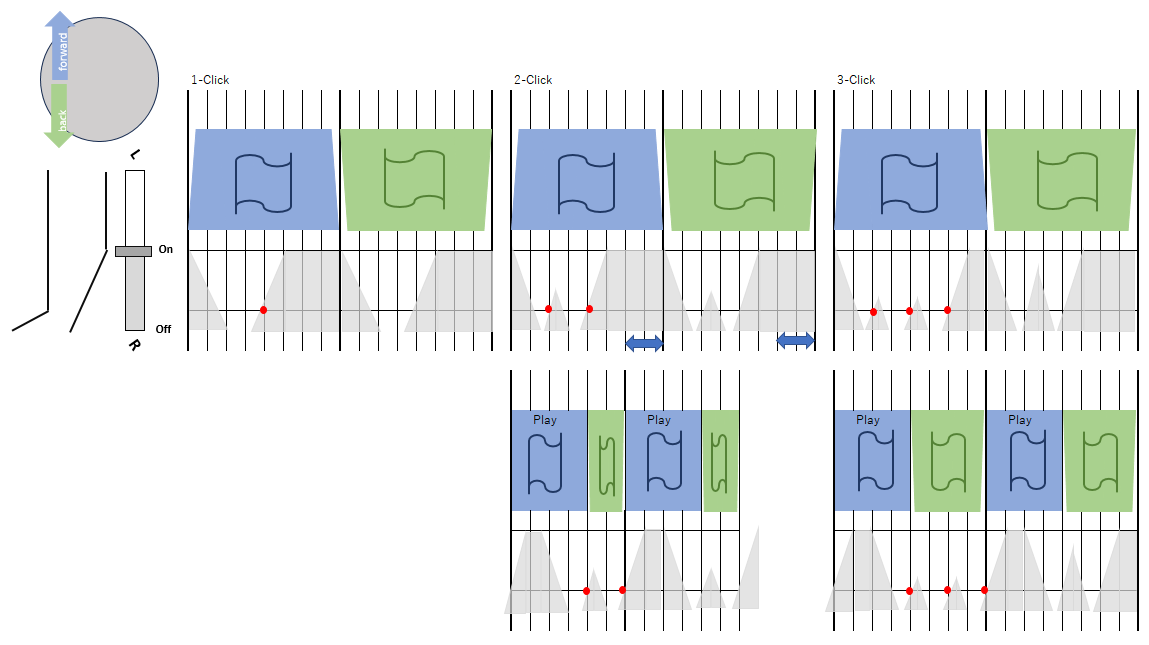
タイトルは、DJのスクラッチプレイでとてもよくつかわれる技の名前です。
以前の記事で、今から10年以上前に購入したDJ Mixerでスクラッチにトライしたことがありましたが、このときの誤解がとけたため、改めてスクラッチをやってみることにしました。
(もともとDJ MixerはイベントなどでノンストップのBGM再生をするのが目的で、テンポの違う曲をデジタルならではピッチそのままのテンポチェンジをしながらつなぐのに快感を感じて使っていました。)
https://beflat.iiv.jp/xml417
その誤解というのは、フェーダカーブをソフトウェアで設定できることを知らなかったことです。(ハードウェアについているものだけと思っていた。)

Serato DJのミキサー設定で、クロスフェーダカーブを一番速くすると、フェーダを少し動かしただけで、すぐにボリュームがMAXになります。
冒頭の図でその違いを表現しました。ONの位置が違うと音の立ち上がりのタイミングが変わるため、リズムが違ってきます。新しいDJ Mixerを買わないとできないと思っていたところ今のものでも十分できるとわかってから、またやる気になりました。あとこの図は、今回2-click flareをやるにあたってまとめたものです。前回なにもわからず、見よう見まねでやったため、今回はきちんとリズムがつくられるタイミングを整理して挑戦しました。
その前に私が思うスクラッチの魅力ですが、ターンテーブルで再生速度を、フェーダで音量をコントールできることから、サンプリング波形再生としては、リアルタイムでなんでもできるということです。本来の波形がなんであれ音を刻んでリズムをつくることはもちろんのこと、上級者になるとピッチすらつくりメロディを奏でたりします。この奥深さに探求心がかきたてられます。
今回はフェーダに焦点を当てていますが、ターンテーブルの操作が難しく、左右の手を動かすタイミングが僅かにづれるだけで、まったく違ったリズムになったり、音がでなくなったりします。感覚的にはバイオリンのような難しさを感じます。
また以前スネアドラムのブラシ奏法を掘り下げたとき、スクラッチのことも頭にありましたが、難易度が高いためスルーしていました。
https://beflat.iiv.jp/xml260
さて本題ですが、スクラッチの動画はYouTubeにたくさんあります。とても参考になるのですが、トリガーのタイミングが理解できなかったため(なぜフェーダのONでもOFFでも音がなるの?などなど)、フェーダの移動を細かく調べました。フェーダに指(爪)がタッチする音や端に当たった音が、実際のリズムと違いますし、位置往復(OFF->ON->OFF)で一音鳴るため、倍のリズムを刻んでいるよう聴こえます。そのため図のような性質を頭に入れながらプレイすると(32分音符/1Grid)、わかりやすく感じました。(神経質すぎ?)
結果、音の出るタイミングというのは、フェーダがONのとき、ONの状態でテーブルのForward->BackおよびBack->Forwardの切り替わりの瞬間ということになります。
2-Click Flareは16分音符分短くして一拍半フレーズにしてつかわれることがよくあります。(<->を削除)
上段の1-Click,2-Click,3-Clickのリズムは
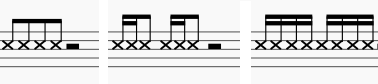
です。
また16分音符分をひとつ分後ろにずらして、頭ふたつ分を通常再生(言葉が正しくなさそう・・手で擦るFowardでないという意味)したものが下段です。(手で擦って普通に再生させようとするとかなり困難なのがわかります)リズムは

です。2-Clickは一拍半が通常だと思うので、そうしました。
頭ふたつは、8分となりたっぷり元の音源をならすことができます。Forword<->Backの切り替えしがなくなるので、1音減るためです。
ここまで、調査結果でした。
これができるかどうかは別ですが、2-Click Flareを挑戦した動画を一応とってみました。
曲は最近カッコいいと思った下記です。
ちょっとテンポがはやすぎた^^;
上達したらまた動画をとるつもりです。
DJのお気に入り動画
「DJ SARA ★ Freestyle Scratch with djay Pro and Reloop Beatpad 2」
彼女の歌うようなスクラッチがとても好きです。
The Distance Between 0 and 1
今回はちょっと長文になります。前回のAIの流れから、マシンと人間と音楽の話です。
この動画は、私が好きなドラマーのJoJo Mayer氏が、電子音楽から新たに派生したジャングルやドラムンベースというジャンルから、ドラマーとしての人生を変える衝撃的な出会いがあったことを、あのプレゼンテーションで有名なTEDで語ったものです。(クール!)
ドラムマシンにプログラムされた人間の能力を超える演奏を彼曰くリバースエンジニアリングし、これを模倣して即興演奏することで、新しいスタイルが確立したことについてデモ演奏を交えて、知的に語られています。本来ドラムマシンは人間の演奏をシミュレートする存在ですが、ドラムマシンの演奏を人間が模倣するということから、リバースエンジニアリングという言葉を使っていると思います。
ドラムンベースは元々好きなジャンルで、彼のバンドNerveでこれをアコースティックドラムでプレイしているのを初めて動画で見た時は、これやりたかったやつだ、と思い一気にファンになりました。
最近、上記動画でドラムンベースをフィンガードラムで懐かしんでプレイしたり、ある本を読んだり、YMO ユキヒロ氏の逝去でマシンフレーズを模倣した動画を作成したことから、いろいろなスイッチが入り、TEDプレゼン動画を題材にブログを書いてみました。
TED動画から引用
「ドラムマシンにプログラムされた作り込まれた演奏と、即興演奏との創造的プロセスにある違いに答えが隠されている。」
「即興演奏では、意思決定が速ければ速いほど楽しく、力がみなぎるように感じる。」
「意思決定プロセスが意識的に処理できないレベル ゾーンに入る。」
ジャングルはプログラミングによるものや、フレーズサンプリングしたものを倍速で再生するものがあり、テンポが非常に速いです。マシンサウンドなので当然ですが、演奏できることを考えていません。
このテンポの曲で、即興性を取り入れてプレイするということは、かなり難易度が高いことはわかります。これがまさにここで言っている意識的に処理できないレベル「ゾーンに入る」ということでしょう。
下記の動画では、マシンフィールを意識したまま、ドラムソロを叩くというすごいプレイがあります。(動画最終部分)
人間的なドラムソロをやる部分もありすが、機械っぽいフレーズを多用しています。後者の方がきっと難しい、というかきついと思います。
TED動画から引用
「デジタル文化のリバースエンジニアリングを続けた結果、「0」と「1」の間の違いや距離に注目するようになりました。おかげで口では説明できない自らの創造性の源と人間の存在の理解に限りなく近づくことができました。ここまでにお話ししたことの意味が皆さんにも伝わるように、今から短い即興演奏をお見せします。」
このように語って最後の演奏に入っていきます。
言葉では十分説明できないから、演奏で説明するぜみたいな、なんともカッコいい・・
実は、JoJo 氏、ユキヒロ氏と幾つか似ている点があると思っています。
マシンフィール以外にも、テクニックについての考え方です。「曲に必要なテクニック」であることです。どちらもドラマーというより、アーティストです。トラディショナルな音楽をベースに置きつつも、新しい音に敏感にであり、それを使った音楽を大胆に実現します。ドラムセットのスタイルがある一時ですが似ていると感じた部分があります。JoJo 氏は、上記動画ではTomがBDの上にセットされる伝統的なスタイルをとっていますが、TomをおかずClosedHHなどの金物をおくスタイルのNerveの動画もたくさん見かけました。またユキヒロ氏も、初期YMOの時代、フロントエンドは全てシンセドラムパッドという構成をとっていたことがあります。BDの上にTomがないセットというのは、ドラマーとしてすごく制約を感じるものです。(ビートマシン化する)逆に言えば、Tomなしセットは、スタイルをがらっと変えられるとも言えます。
あとドラム音色のこだわりが両氏ともすごいです。ユキヒロ氏は電子音やエフェクト音について、クールな音をたくさん作り出しました。JoJo氏のすごいところは、それをアコースティック楽器で実現するところです。サイドSDにリング状のシンバルを重ねたりなど、ほとんどオリジナル楽器です。
BD4分打ちリズムのクラブサウンドではスネアを使い分け、グルーブをだしたりしています。
通常Roland TR-909 BD系の4分ダンスビート曲は、その音色自体が重要なのでアコースティックが入る余地はないのですが、太いアナログベースのNerveの楽曲に、JoJo氏の研究されたプレイが乗ると十分アコースティックでもいけています。これもリバースエンジニアリングの結果として個人的に衝撃的な出来事と感じました。
動画に戻りますが、タイトルの”between 0 and 1″と言っている部分、デジタルかアナログか、と言っていないことが気になりました。先に、意識的に処理できないレベル、について少し触れましたが、処理速度に関して言っているのなら、量子コンピュータを連想させます。ただ単に分解能のことかもしれませんが、それだとゾーンに入る、などという深い意味にならないような気がしたからです。(余談ですがKorgのVolca Drumではフレーズを確率で変化させることができあます。これだけでも即興に近い印象を感じます。ちなみに関係ないですが量子コンピューターは確率を使って計算をします。)
最近ジョージ・ダイソン氏の「アナロジア」という本を読みました。奇しくも帯には「0と1に寄らない計算は人類に何をもたらすか?」「ポストAI時代の予言書」とあります。著者のインタビュー動画がありますので最後に引用しておきます。
私がこれを読んで感じたのは、自然とか人間にもう一度目を向けることの重要性です。技術的にはデジタルよりも高性能なアナログコンピュータについて書かれていますが、(といってもほとんどは自然界の話)これはナチュラルコンピュータと言われるものと同義だと思っています。量子コンピュータもその一種ですが、自然界が行なっている計算の方が人間が作るコンピュータよりはるかに速いということです。(デジタルコンピュータはシリアライズという特徴を持つため)
量子の自然現象としての演算について、下記動画は私の理解を深めてくれました。
【誰でも量子コンピュータ!量子機械学習編】Quantum Computing for You【第3回・9/22実施】
イジングモデルと組合せ最適化問題の対応
過去関連記事)
「量子コンピュータプログラミング」
https://decode.red/ed/archives/1421
「Qiskit」
https://decode.red/blog/202301151549/
「Quantum Computer」
https://decode.red/blog/202301031525/
「Artificial Life」
https://decode.red/net/archives/560
「Cellular Automaton」
https://decode.red/net/archives/547
「アナロジア」から引用
「人間の言語は、独立したジェスチャーの連続から進化したもの、あるいはそれと共進化したもので、ノイズの多い低周波帯域での貧弱な伝送に耐えるように最適化されている。このようは制約を受けない知性の間では、まったく異なる言語が生まれるかもしれない。クジラがコミュニケーションをとっていることは間違いない。しかし彼らはわれわれが言語で考えを伝える時のように、知能を不連続の記号の連なり変換する必要はない。われわれが音楽を演奏するとき、クジラは「やっとわれわれと同じようにコミュニケーションしようとする兆しが見えた!」と思っているかもしれない。」
自然界はもっと高度はコミュニケーション(あえて通信と言った方がテクニカルに感じやすいかも)をしているのでしょう。音楽によるコミュニケーションは即興演奏などで体験できます。言葉より具体的な意思の伝達には不自由かもしれませんが、先にJoJo氏が言ったように言葉では説明できないことも伝えることができます。これは本当に興味深いことです。
むしろ言葉には誤解がつきもののことを考えると、言葉より優れているのかもしれません。音楽や絵画などのアートによる非言語の伝達手段というものを人間がさらに身につけることができれば、相互理解能力が高まり、その結果さまざまな誤解を減らすことができるかもしれませんね。
即興演奏によるコミュニケーションの速度は、現在のデジタルコンピュータでいかにプログラミングしようとも(何台もネットワーク化しても)、人間にはかなわないだろうという感覚があります。コンピュータはバッファリングによる遅延というハンデがあったり、人間の先読みする能力までシミュレーションする必要があります。(ニューラルネットワークアナログチップのようなものが必要)
人間の能力が奏でる音楽を機械で模倣し、またその音楽を人間が模倣して新しい音楽が生み出されました。身体性が音楽に影響を与えてるでしょうし、音楽が身体性にも影響を与えます。(ドラムンベースで先の「曲に必要なテクニック」といわれるものを考えたとき、Push-Pull奏法というものが使われています。コツをつかむのが難しいのですが、片手で高速に連打できます。これをJoJo氏は足でもやっている。)将棋AIが棋士に変化をもたらすように、テクノロジーが進むとともに人間の感性も変化していくことでしょう。そして次の音楽は・・また別のレイヤーでの人間からマシンに対するアプローチだと思っています。つまり行ったりきたりするわけですね。
最後になりますが、おまけとして追記します。
マシンフィールのプレイの難しさを実感した、動画についてです。
マシンビートを模倣したことで新しい奏法に挑戦しました。珍しくコメントをたくさんいただき恐縮です。
今回の話題にもつながるので、この動画に込めた意味も少しお話しします。
動画と撮ろうと思った動機は、もちろん多大な影響を受けたミュージシャンのユキヒロ氏の逝去で、このタイミングに何か爪痕を残したいと思ったからです。選曲したU.Tは、とても興味深い位置付けの曲なので選びました。この曲はライブでは演奏されたことがない曲です。ドラムはもともと8ビートのパターンを、16分音符分ディレイをかけているため、音数が倍になり16ビートのリズムになっています。元が8ビートなのでテンポの速く、ドラムセットで再現するには、かなり悩むパターンです。最終的に、手で16ビートをシングルストロークで叩くのは、きついのでダブルストロークを混ぜました。そうするとBDのシングルストロークに合わせるのが辛くなりますが、この方法にしました。(テクノは修行)
次はイントロですが、ここではマーチングドラムのエッセンスが入っています。JoJo氏がジャングルやドラムンベースを即興でドラムプレイしたいと思うのと同様、このエッセンスをドラムセットでプレイしたい、という思いが長年ありました。(奇しくもJoJo氏のプレイの中にもマーチングフィールがよく見られます。ハイピッチSD上のスティックショットなど)このセットは通常のツインペダルで叩くBDの他に、その左右にBDペダルを置いて音程感のあるBDの演奏ができるセットになっています。YMOの楽曲には、Roland TR-808のBDやTomを使った音程感のあるシーケンスフレーズがよくあります。UTのイントロも同様で、この音はマーチングの音程感のあるBDの音とよく似ているのです。そこで今回これの一部を使ってイントロを再現しました。あとMC部分のクロススティキングですが、これもテナードラム(クイント、クォード)でよく使われる奏法です(太鼓が三つ横に並ぶと使える)。ルックス的にもフロントの4パッドはYMO初期のシンセパッドのオマージュです。シモンズの音は初期にはありませんでしたが、この製品があればきっと使われていたことでしょう。初期の楽曲にもマッチする不可欠の音と思っています。
長くなってしまいましたが、あのとき何を考えていたっけ、というとき思い出せるように、というつもりで書きました。
本来のブログ(Web Log)の役割とはこういうものだと、言い聞かせて。。
【ChatGPTの次はアナログ社会が来る】科学史家ジョージ・ダイソン氏の不思議なポストAIの予言/AIが自然のように成長する/人類の運命とは/難解で不思議な『アナロジア』を刊行した意義
【ChatGPTのペット化】世界的科学史家のジョージ・ダイソン氏/AIは野生化し、アナログの時代が始まる/ChatGPTの出現の希望と課題とは【後編】
Attention Is All You Need
“AI時代の生き方に、音楽は様々なヒントを与えてくれるかもしれない”
このBlogの副題ですが、それゆえAI を取り巻く話題についてこれまでも取り上げてきました。
https://beflat.iiv.jp/xml773
https://beflat.iiv.jp/xml714
ChatGPTをはじめとする生成AIについて、今回はその仕組みについて掘り下げてみました。
(仕組みをわかりやすく説明するものでなく、私が学習した備忘録のようになっています。)
タイトルは下記論文のものです。
https://arxiv.org/pdf/1706.03762.pdf
まずは用語の説明です。
GPT:Generative Pre-trained Transformer
Chat GPT :OpenAIが開発した、大規模言語モデル(LLM:Large Language Model)であるGPTを使ったチャットサービス
Transformer :従来から使用されてきたCNN やRNN と違い Attensionと呼ばれる仕組みに基づいたエンコーダデコーダモデル
CNN:Convolutional neural network 畳み込みニューラルネットワークといい画像や動画認識に広く使われているモデル
RNN;Recurrent Neural Network 再帰型ニューラルネットワークといい時系列データ(株価や気温の推移等)の扱いに最適
参考動画
【Transformerの基礎】Multi-Head Attentionの仕組み
https://www.youtube.com/watch?v=XOekdMBhMxU&t=166s
もともとは言語翻訳の分野で研究され、学習するときにどこに注目するか(どのデータに注意するか)といった情報が付加されることによって従来のLSTMなどによる方法より高い性能を上げられるようになりました。
これがTransformerというモデルです。ChatGPTはPre-trained(学習済み)ですので、デコーダのみを使います。
構造について論文から引用
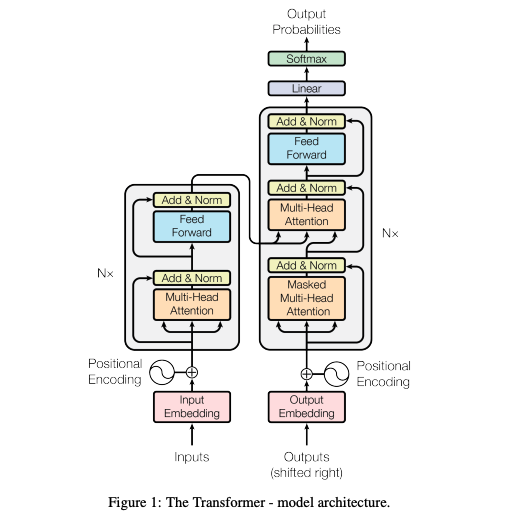
LSTM :(Long Short-Term Memory: 長・短期記憶) ネットワークは、RNN(再帰型 ニューラル ネットワーク) の一種
LSTM の強みは、時系列データの学習や予測(回帰・分類)にあります。
一般的な応用分野としては感情分析、言語モデリング、音声認識、動画解析などがあります。 (https://jp.mathworks.com/discovery/lstm.html より)
Scaled Dot-Product Attention、Multi-Head Attention、QKV
構造について論文から引用
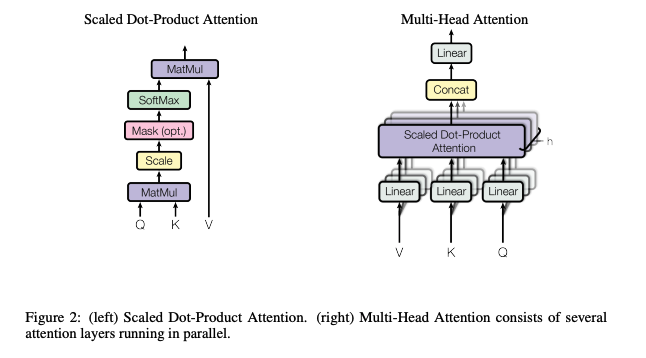
マルチヘッドアテンションについて
https://cvml-expertguide.net/terms/dl/seq2seq-translation/transformer
“Transformerの設計は,マルチヘッドアテンションを主要ブロックとして採用したのが,最大の特徴である.マルチヘッドアテンションは「系列内自己アテンション or 系列間相互アテンション」アテンションの役割を担当する”
参考動画
https://www.youtube.com/watch?v=g5DSLeJozdw&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ
画像のセルフ(自己)アテンションを例にわかりやすく説明されている。
Query ,Key,Valueの違いについて
https://www.youtube.com/watch?v=50XvMaWhiTY&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ
V=K=Q=入力X だが これに行列をかけて回してあげる、Q ,Kそれぞれ回転させてから内積をとる、Vも回して出力調整
様々な角度からXの横ベクトルを比較して、どこに注目するかを制御して出力を決定するのが、Multi-Head Attension.
ChatGPTの仕組み
参考動画
https://www.youtube.com/watch?v=om-PZpvnCBM&list=PLfZJp4OG6U1Evr74E_k7P8zqb6MX9KKUZ&index=13&t=132s
仕組みについて理解するのは難しいですが、誤解を恐れずに言うならば、従来のLSTMでなく、TransformerのモデルがたまたまうまくいったためChatGPTのようなものが生まれた、と言えるかもしれません。(必要なのはアテンションだけ。構造に能力が宿るのだろうか・・これがすごく気になります)
ニューラルネットワーク自体、人間の脳の仕組みを模倣したものをコンピュータ上に実装しています。これを使うと画像認識など、データから答えを求めることができてしまいますが、なぜその答えが出たのか、そのプロセスの説明は困難です。Transformerも同じように考えられます。この先、意識は? 感情は? といったもの(モデル?)についても研究が進むのでしょう。 (偶然、感情に適したモデル(構造)ができちゃった、なんてことがあるかも・・)
さて、ここからが本題ですが、楽器などを練習していて思うのが、これってリアルディープラーニングかも、と思うことがあります。(もちろん人間が本家なのでおかしな言い方ですが)
同じフレーズを繰り返し演奏して、少しずつ上達する様子が、AI による学習に似ていると思うことありませんか?(音楽は時系列なのでRNNか)
特に、上記のセルフアテンションの仕組みを知った時、これはドラムプレイに当てはまっているのでは、と思いました。
ドラムセットをプレイするのを見て、よく手足がバラバラに動いていると思われる方は多いです。しかし実際には右手と右足、左手と左足は連動して動いていたりすることがあり、右足に注目して、右手の動きをする場合や、左足をタイムキープの軸にしたるすることがあります。
つまりどこかに注目(アテンション)するわけですが、これを変えると全く別の体の動きとなり、また新たに違うパターンとして練習をし直す必要があることがあるます。
ドラマーにしかわからないかもしれませんが、簡単な8ビートのパターンを叩いている時に、左足を4分で軽く踏んでいるとします。このとき左足を4分の裏で踏むように変えると、一気に叩けているはずの右手、右足、左手がぎこちない動きになります。(Positinal Encodingが影響するか)
筋肉の動きには問題がなくても、神経の働きが学習されていないせいなのではと思っています。
下記投稿の動画のイントロ部分もそうなのですが、Swingということで左足を裏拍で踏んだら一気に難しくなってしまいました。
https://beflat.iiv.jp/xml784
まあ飛躍的な考え方と思われかもしれませんが、脳が手足にどのように指示を出しているのか(先読み、条件反射、・・)、個人的にはとても興味深いテーマです。
AI研究が進む中、音楽が果たす役割は大きいと思います。
先ほどの、意識、感情、に続いて、創造力にもモデルがあるのだろうか。
Swing Vibes
今年も、ドラムマガジン2023誌上ドラム・コンテスト曲にトライしてみました。(Roland TD-17)
今回は好きなタイプの楽曲ということで盛り上がってしまい、欲張っていろいろなことにトライし(てしまい)ました。
一つは、以前からやりたかったチューニングタムです。アコースティックドラムでは古くはペダルがついたチューニングフロアタムなるものがありましたが、普通(?)は片方のスティックや指で、ヘッドを押さえつけたりしながら叩き、ピッチが変化した音をプレイします。今回IoTでよく使うデバイスM5StickCを使い、ピッチを変化させることを試みました。最初はTD-17にダイレクトでBLE接続を試みましたが、つながらずWindows PC 経由でコントールすることにしました。(右手首の角度でハイタムのピッチがかわります)そのため、少しレスポスが遅れるのと解像度が粗いところがあります。また発音中の音が変化しないのはちょっと残念でした。(いい感じに変化させるのは結構難しい・・Rolandさん一緒に開発しませんか?なんちゃって)
もう一つは、愛用のMicrofreakのファームウェアがversion 5になって、サンプルのリバース再生ができるようになったので使ってみました。偶然にも課題曲のイントロを聴いたとき、これしかない、という音が見つかりました。
あとはタイトルがSwing~ということもあり、久しぶりにレギュラー(トラディショナル)グリップで叩いています。レギュラーグリップでたたいてみて一つ発見がありました。エレドラの音が違うのです。メッシュヘッドの瞬発力を今までマッチドグリップが押さえつけていたのがわかります。スティックが弾みやすいため音切れが良い感触がします。(軽やか)また左手のハイタムへの移動がスムースなので最後はスティーブガッドの頭抜き6連符の連打でエキサイトしてしまいました。グリップはプレイスタイルに大いに影響を与えます。しかしこのグリップの弊害もありました。ついついスティックを回したくなりプレイにリスクが増えてしまいました。おまけでマーチングスネアでよくやヘッドを押さえつけるプレイもやりたくなり、エレドラでトライしています。(ダブルストロークの2打目、しかし効果はあまりなし)
以上、考えることがありすぎて、頭の中が大混乱しながら叩くことになりました。(最初は左手にもM5StickCをつけてスネアドラムのピッチも変化させていましたが、レスポンスが遅れることでコントロールが難しいことから断念)
しかしながら、いろいろやりながら、まだまだエレドラの面白い使い方があることがわかりました。これからどんどん追及していきたいと思っています。
Kit59 でハイタムのピッチを変化させる、MIDIメッセージデータ
[0xf0, 0x41, 0x10, 0x00, 0x00, 0x00, 0x4b, 0x12, 0x03,0x75, 0x03, 0x01, 0x00, 0x00, int(pitch/16), pitch%16, chksum, 0xf7]
ToDo ピッチダウンができなかった。
参考)
TD-17 MIDI インプリメンテーション (Version: 2.00) [PDF]
https://www.roland.com/jp/support/by_product/td-17/owners_manuals/7f9e7c7c-f6f1-4b42-8057-c721b104100f/
M5Stickについて
Generative Adversarial Networks
生成AIについて下記でも扱いましたが、今回はもっと掘り下げてドラムトラックの生成をやってみました。
メカニズムについてはGenerative Adversarial Networks(GAN:敵対的生成ネットワーク)というものですが、下記でプログラミンコードを走らせていいます。
https://decode.red/ed/archives/1384
上記では、jupyter notebookをつかって一つずつ作成しましたが、このサイトのもとになっている下記サイトでは、大量に生成できるスクリプトが用意されていますのでこれを実行してみました。(Macの場合cudaは使えませんが、Apple Siliconでmps:Metal Performance Shaders指定するとcpuの倍くらいの速度で生成できます)
https://github.com/allenhung1025/LoopTest

デモサイトで音を聴くこともできます。
https://loopgen.github.io/
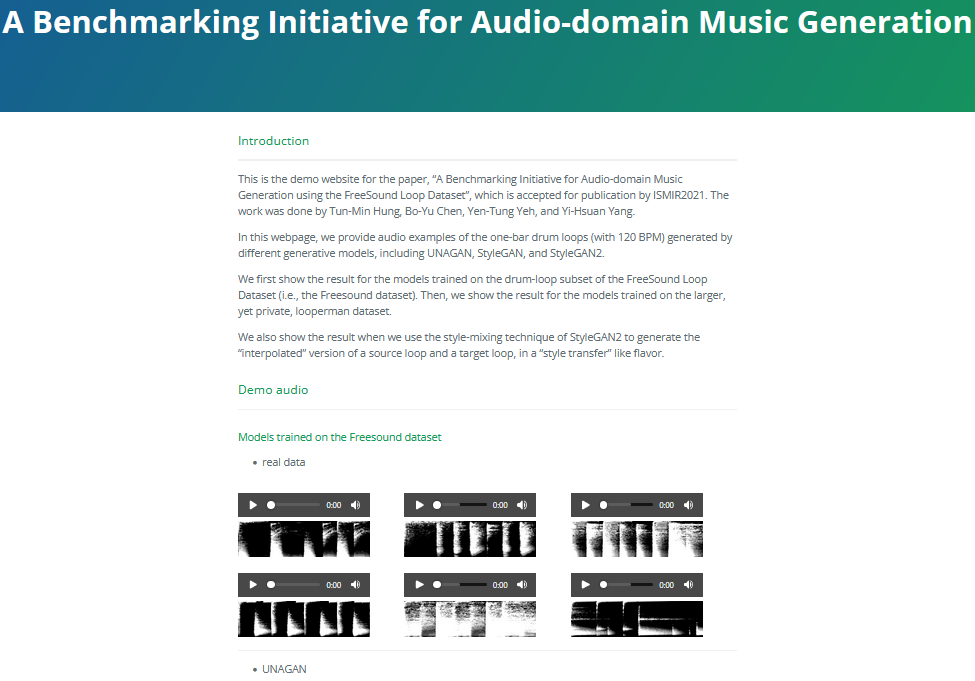
下記はJupyter notebook(OSCサーバ)とMAX/MSPを使ったリアルタイムクロスフェード再生のデモ動画です。
https://github.com/naotokui/LoopGAN
私も動かしてみようとしたのですが、MaxとJupyter nodebookは両方ともMacで走らす必要があるため環境面で断念しました。
(私のMaxがつかえるMacが古い。Maxパッチを変更してリモートでWindowsとOSC通信まで動きましたが、ファイル共有もする必要があり、また機会があったらトライします)
ということで波形編集ソフトクロスフェードして雰囲気を味わいました。
通常のドラムトラックのクロスフェードとちがって、元のドラムトラックがGANで生成されていると学習したドラムトラックのバリエーションで生成されるので、クロスフェードのつながりがよいように感じます。
モーフィングのようなイメージか。
下記は、実際のパフォーマンス、とてもクール!
“A performance of “Emergent Rhythm” — a realtime generative DJ set performed by Nao Tokui”
https://www.freethink.com/robots-ai/nao-tokui-and-dadabots-want-to-create-new-music
Finger Drumming / SP-808
最近ネットで動画を見ていて、フィンガードラミングというものをやりたくなりました。AKAIのMPCシリーズがこの世界では昔から有名ですが、20年以上前に購入したRoland SP-808(1998年発売)があるのを思いだし、これでできるのかどうか試してみました。
まずデータ保存されているメディアが特殊であるため、ZIP Drive(取り外し式のバードディスクのようなもの)が無事か、そしていくつかあるメディアに何が入っているかを恐る恐る確認しました。
当時同梱されていたデモのデータを編集して、問題なく演奏のためのセットアップできてほっとしました。当時流行っていたJungle Drumming soundがいっぱい入っていて懐かしいです。
このマシンはとてもユニークな機能を多数持っており、これが面白くて買いましたが、一番実用上優れていたのは、長尺のフレーズサンプルを同時にポン出しできることではないでしょうか。そのためZIP Driveになっています。音楽以外にも映像などにセリフをつけるのにも便利でした。実際、ゲームイベントでデモ動画にあわせてライブ演奏をしたこともあります。
昔は個人の機材で仕事をすることを当たり前のようにやってました。会社で購入してもらえないわけではなく、自分がほしい機材で創作をしたいからです。最新のシンセがでるとメンバーの誰かが買って会社に持ってきていました。
さてフィンガードラムの結果ですが、駆動しているトライブの上をぶっ叩くことに抵抗がありますね。ZIP DriveにOSが入っているため、ドライブが破損したらアウトです。楽しいのですがこのようなことはあまりやらないほうがよさそうです。フィンガードラムテクについては、修行がいることがわかりました。
また実際に使っている動画も見つけました。Sketch Showのライブで細野さんが使っています。
https://www.youtube.com/watch?v=tXUQQKchGuc
52:03あたり
このようにYMO関連の動画をついつい見てしまうのですが、当時を思い出しながら自分のいろいろなスイッチが入っているのを感じる今日この頃です。
YMOの時代の音楽は、右肩上がりの社会が大きく影響していると思います。
もっと具体的に言えば、半導体メモリの容量、CPUのbit数、周波数、これらがダイレクトに影響しています。新しいシンセやサンプラー、エフェクタなどの機材が発売されるたびに、新しい音、聴いたことがない音に出会えました。
語弊があるかもしれませんが、一方向に進化してきた音楽、PCがひととおり音楽を表現するのに十分な性能をみたしたあとは、聴いて驚くような音に出会うことは少なくなりました。それと同時に時代の先端を感じる音楽は少なくなり、これまで古い音楽とされてきたものが逆に新しく感じるようになり一巡しました。音楽を創る人も、聴く人も多様化し、ビジネスモデルも大きく変化しました。
最近、多様性のある社会がさかんに提唱されています。エントロピーが増大するがごとく、時代の流れは制約のない自由の方向に進んで行きます。このブログでも以前、自由がゆえの不自由、不自由がゆえの自由というものを音楽の創作の過程で経験したことをとりあげました。学校生活の校則にたとえていうとと、統一された制服という規則の中で、いかにおしゃれをするか、人と差別化するか、という創造性というものと似ています。私服が校則になると、されらに創造の幅は広がりますが創造性が増すかといえばそれは別で、毎日着る服選びに、すくなくとも制服のときよりはエネルギーをつかうことになります。(スティーブ・ジョブズはそのため毎日黒のタートルとジーンズだった)どちらが良いのかは人によって違いますが、こういう関係にあることをとても興味深く思っています。
音楽の世界は、過去の多くの人が知っているアーテイストのような成功を収めることはかなり難しく、コニュニティーやサロンのような、単位での成功になるのではと思われます。これは社会の単位が小さくなってきている証拠で、これまで大きな枠の中のルールに従っていれば安心だったものが、この枠が細分化、多様化されることで個人が埋もれる可能性が高くなってきました。
多様性の社会では、個人の存在感を高める努力も不可欠になるのではと思っています。
このように音楽を通して社会を見ることを、このブログではよくやっていますが、最近ではなんといっても生成AIの話題でしょう。
私もいろいろ試していますが、今の段階で画像にくらべて音楽のクォリティがかなり低いと感じています。やはり時間軸という次元がひとつ多いので難しいのでしょう。しかしアートも音楽もいくらAIがすごい作品をつくったとしても、人間の趣味が多様化した現在、その一つが与える影響は、少ないでしょう。(一つのコミュニティにすぎない)またすごい作品ができるのならそれはそれで素晴らしいことだと思います。
また脱線続きの投稿になってしましたが、多様な話題がこのブログです。と、いえればかっこいいのですが、ただまとまりがないだけ。
May you rest in peace
YMOメンバーのお二人がつづけてお亡くなりになり、寂しい気持ちとともに当時熱中した記憶とさまざまな感情も思い出されてきました。YouTubeでのYMOに関する過去動画がこれに拍車をかけています。
前回投稿から少し落ち着いた今、ちょっとだけ自分にとってどういう存在だったのか、整理してみたくなりました。
(下手なのに、今どうしても弾いた動画をつくってみたかった。。)
何に一番熱中したかと言えば、やはりアナログシンセサイザーでした。当時名古屋の大須やヤマハの店頭にあったことを記憶しています。得体のしれない音ができる装置ということで夢中でいじりました。楽曲よりもそちらの興味が大きかったです。
楽曲を深く掘り下げたのは、ゲーム音楽を作る仕事をしているときで、仲間もみんなYMOフリークであることもあって音作りのときに、YMOの話題でもちきりなりました。教授が最後まで愛用していたシンセ、プロフェットファイブは憧れの楽器で、高価で買えないためその音をSoundCanvasでシミュレートしたりしていました。この時代、彼らの新しい試みが刺激的で、音楽が自由で楽しいものであることを満喫していました。そのため一挙手一投足に反応していた時期もありました。たとえばドビュッシーが好きだといえばそれを聴き、高橋悠治氏と対談したといえば、その人の本を買ったりといった具合です。教授をハブとしていろいろなことに興味をもち、こういった刺激から創作意欲が掻き立てられるという習慣がつきました。それゆえ新しい刺激があるたびに、現在でも自分にしか作れない音楽があると信じ込むような始末です。
技術面では教授のハーモナイゼーションか好きです。あの親しみやすい「戦メリ」のメロディーにも4度下の音が倍音のようにくっついていて、深みを出しています。「邂逅」もそうですが、音色としてハーモニーというのか、聴いたことのない音のイメージを感じさせます。また「千のナイフ」などにある無調的な部分も好きで、こんなカッコイイ聴かせ方があるのか、と驚きました。(この後無調音楽についてのめりこんだのは言うまでもありません)またキーボードプレイ全体についてとても好きで(ライブも)、U.TのMC部分、「高橋さんのドラム、すごいですね」ですが、「坂本さんのシンセパッドもずこいですね」といいたくなります。
(練習不足でスミマセン、パターンの繰り返しがきつい。。40年以上前の楽曲とは思えない新しさ。ライブでは演奏されていない曲だが、どうやった叩こうかと思わせる曲。)
シンセサイザやサンプラーの技術がこれ以上できないことはない、というところまで行き着くと、新しい音に刺激を受けることが少なくなりました。また音楽も多様化して、かつてほど影響力のあるものが出現しにくくなってきたと思います。その中でもまだ新しいものが作れると信じています。教授が晩年レコーダを街に持ち歩ている音をサンプリングしている姿を動画で見ましたが、とても嬉しくなりました。さすが、今も昔も変わっていないと。
音楽にはいろんな楽しみがあります。聴くこと、演奏すること、作ること、学ぶこと、妄想すること、などなど、どれも深く無限に楽しめます。これを通して成長し、そして様々なことに目を向けさせてくれます。YMOのメンバーは若い時期に音楽の面白さについて膨大なインプットを持っていたことがすごいと思います。当時は今ほど簡単に情報を入手することが簡単ではなかったことを考えると、相当精力的だったことが想像できます。彼らを夢中にした音楽もあるわけですから、やはり音楽の力は偉大と言えます。
音楽に夢中になれることは、幸せなことです。また平和な世の中でないと音楽を楽しめません。このことを人一倍形に表していたのは教授かもしれません。
次の世代のために、引き継がないといけないと、あらためて思いました。
最後に、明るくて楽しくて自由な音楽「い・け・な・い ルージュマジック / 忌野清志郎 + 坂本龍一 【))STEREO((】」YouTubeより引用します。
Ars longa, vita brevis.
また衝撃的なニュースが飛び込んできました。教授の訃報です。
1月のユキヒロ氏の訃報から間もないこともありとてもショックです。
音楽に対する実験的な姿勢には、とても影響を受けました。このようなブログを書いているのも元をたどれば教授にいきつきます。
YMO時代のヒット曲も好きですが”B-2 UNIT”,”音楽図鑑”,”未来派野郎”といったソロ作品がとても好きでした。また”戦場のメリークリスマス”のような美しいメロディーも好きですが、シンセ、サンプリングを駆使したノイジーでマッドな教授にはとても刺激を受けました。音に対するあくなき探求には、そのベースには音という本質的にものに対するものへの好奇心、音に対する敬意があるからなのではと思っています。世界の音に対する興味、それは音という自然への興味であり、これが教授の環境問題などの活動に現れている気がします。こういう政治につながる活動は誤解を生みやすいので、表現が非常に難しいと感じたことがあります。(政治活動をする動機というのは人それぞれ違いますが、正反対の意図を持った人が同じ運動をしていることもあるからです。影響が大きい人は本意でない利用をされることもある。)
闘病をしながらの創作活動に、この人だからこそこのような偉業を残せたのだと確信しました。
人間だれしも死はおとずれますが、その人の思い出は残り続けます。タイトルの言葉は、インフォメーションからの引用ですが、今これを痛感しています。
あらゆる栄誉をすべて手にいれたようなアーティストで、これに憧れて関連する様々なことに関心をもつこととなり、そのおかげで充実した音楽ライフを過ごせました。
ご冥福をお祈りいたします。
 Ars longa, vita brevis.
Ars longa, vita brevis.
「芸術は長く、人生は短し」
4月8日追記
Prompt Engineering
生成系AIが最近話題になっていますが、私も下記ブログでいくつか取り上げました。
ChatGPT
https://decode.red/ed/archives/1314
Stable Diffusion
https://decode.red/ed/archives/1335
Text2Music
https://decode.red/ed/archives/1349
これらすべてテキストでAIに対して指示を出して、その結果を得るものです。
“ChatGPT”はテキストを返して会話を、”StableDiffusion”は画像、そして”Text2Music”は音楽を生成します。このようなTextによる対話的な操作のことをプロンプトエンジニアリングといいます。コンピュータを詳しく扱える人ならコマンドラインの入出力をイメージするとわかりやすいでしょう。
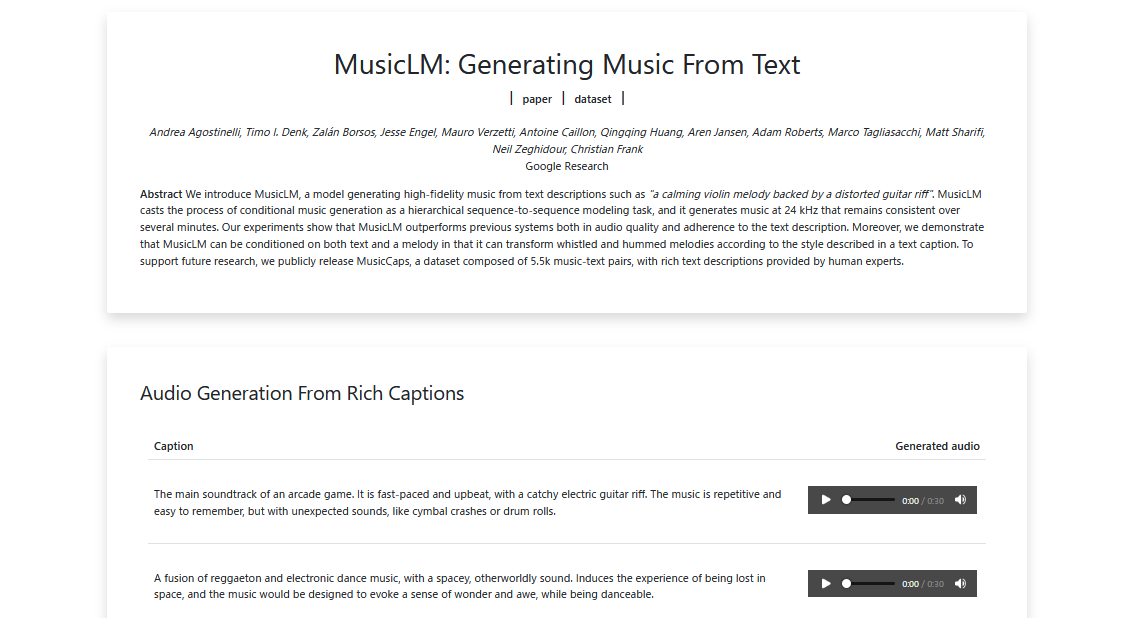
下記の一つ目の例では、アーケードゲーム音楽を作るように指示を出し、それにつづいてどんな曲にするのか説明を加えています。
https://google-research.github.io/seanet/musiclm/examples/
また違うサイトですが”Text2Music”ではmubertのサイトをつかって音楽を生成してみました。
https://mubert.com/render
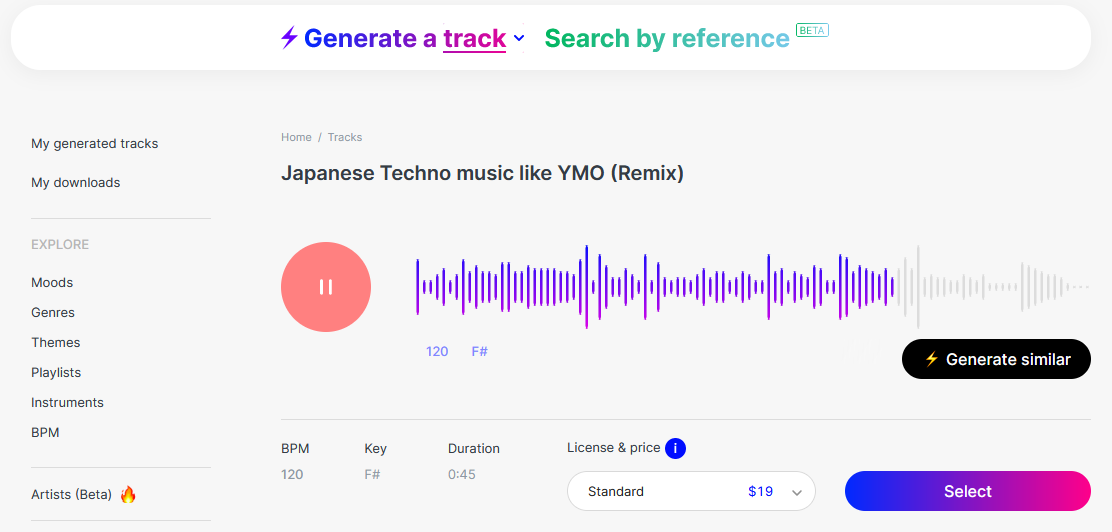
うーん、ちょっとイメージがちがいますが、一応生成しました。
生成系AIでは、入力された画像や音声などに対して、指示を出すこともできます。たとえば~風の音楽にしてとか、鼻歌から伴奏をつくったりとか、できるようです。そのうち自分の歌や演奏に、リアルタイムに伴奏してくれることも可能になるでしょう。
ここで思うことは、これができたとしてどのような未来を想像したらいいのだろうか、ということです。前回の投稿”IOWN / NTT”、ではリアルタイムで遠隔地と人と演奏する話題でした。また最近の画像処理では、自分と違う人の顔であたかも自分が話をしているように見せることもできます。OpenAIのChatGPTで驚いたことの一つに、文章の構成力でしたが、翻訳の精度にも驚かされました。(音声のテキスト化ではWhisperがあります)これらが簡単に扱えようなの世の中になったとき、人類のコミュニケーションの仕方が劇的に変わると思っています。(音楽によるコミュニケーションはさらに高度なものに。あらゆるチームプレイが高度化)
Text2〇〇でつくられる画像や音楽が、人の創造性を超えるとかアーティストの仕事を奪うとか言われることがありますが、私はそれはないと思っています。それができたしてもそこに面白さがないからです。(面白いことは自分がしたいから)また私の専門分野でもありますが、ローコードやノーコードの流れの中、さらにChatGPTによってプログラマの仕事が少なくなるなどとも言われます。しかし少なくならないといけないのではと思っています。
インターネットが普及する前、「ソフトウェアクライシス」という言葉があったのをご存知でしようか。今後このままでは何十万人のソフトウェアエンジニアが足りなくなる、という危機の話です。当時はそれぞれのソフトハウスで独自に開発をしていたため、ソフトウェアの開発効率も悪く、工数がかかっていました。しかしインターネットが普及してオープンソース開発が当たり前になってくると、そのようなことを聞かなくなりました。オープンソースというのは、プログラムの設計図となるソースコードを公開するということです。当時は企業秘密に近いものがあり公開などとんでもない、といった風潮でした。それが今では公開した方がバグの発見確率も高くなったり、プロダクトに参加する人が増えることから、品質もあがるなどのメリットがあります。なによりも大量のコードを再生産できたことで社会のITインフラを支えことにつながりました。これから先さらにITインフラが高度化、複雑化するにあたり、大量のコードが必要になります。(次のクライシスはAIが解決) ITエンジニアの仕事の種類はどんどん変化しますが、これに携わらなければならない人は減らないと思っています。
ここで一つの教訓があります。未来を予測するときに現在の延長で考えるとよみ誤ります。このままでは~になる、という悲観的な予測が世の中にはあふれています。
ITに関しても労働力人口の減少をAI、ロボットがカバーするという考え方と似ていますが、次の社会課題の解決にAIが不可欠になってきたことが、次第に現れるようになってきた気がします。一番深刻な課題という意味では、環境問題や戦争ですが、前者はテクノロジー、後者はコミュニケーションが解決に寄与すると期待しています。
IOWN / NTT
離れた場所で通信を使った音楽のセッションは、古くから多くの人がさまざまのアイディアを試してきました。
まさに夢の技術とされてきたものが、NTTのIOWN(Innovative Optical and Wireless Network)の低遅延通信により実用段階に入ってきました。(動画では東京大阪間往復16ミリ秒(以下ms)という説明)
これについていろいろと推測しながら考えを整理していきたいと思います。
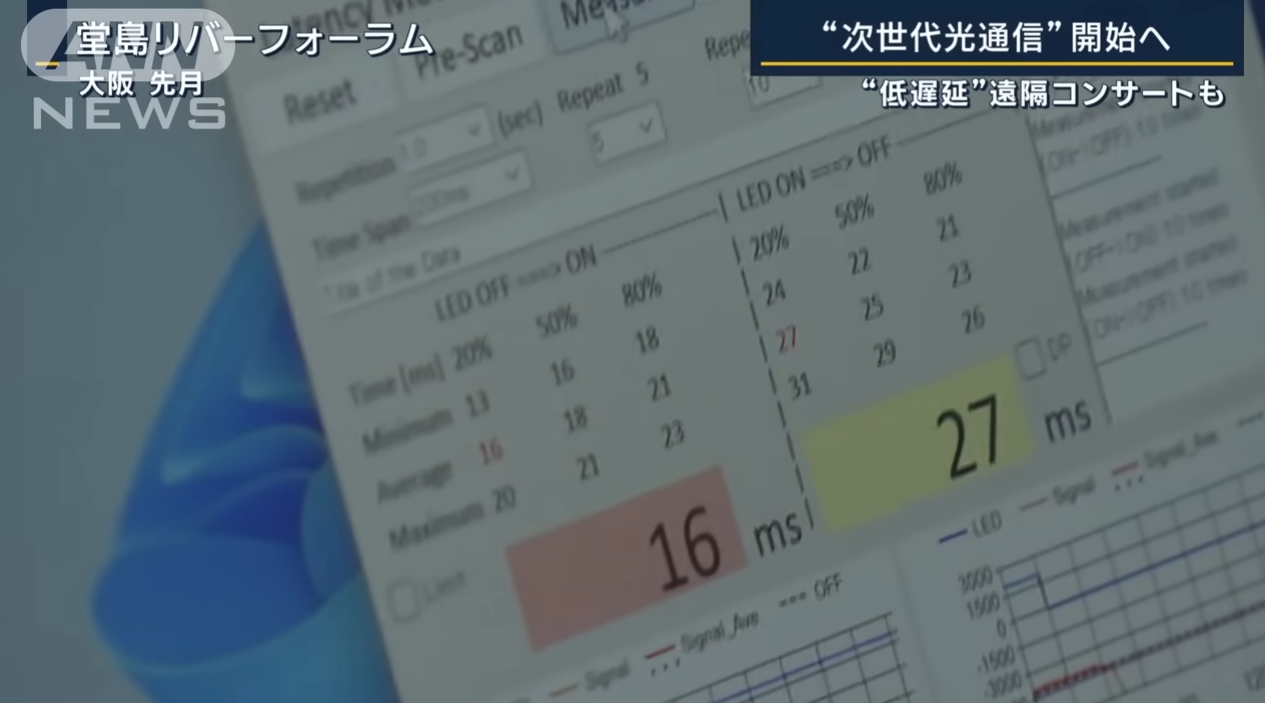

技術の進歩とともに帯域が広くなったことで送れるデータは多くなりましたが、物理現象として今も昔もケーブルを伝わるデータに遅延があるのは同じです。これ以外の遅延の原因は、データ圧縮・解凍によるバッファや、中継器のバッファ、通信を安定化させるためのマージンとしてのバッファが考えられます。(帯域が広くなることによるデータ圧縮の不要、光によるシンプルな中継器、安定したインフラ、これらによって遅延要素は減少)
時間軸で圧縮するようなエンコーダだと演算に必要なある程度幅のあるデータをバッファリングするため、これは実感できるのですが、中継器やインフラについてはあくまで推測です。
動画だと、実験でどのようなインフラを使ったのかわかりませんが、光ケーブルの専用回線ならかなり安定感はあるはずです。(IOWNのWがWirelessなのでこれは遅延要素だと思いますが・・)

物理現象としての遅延は、相対性理論から、最速でも、真空中における光速の値は 299792458 m/s(約30万 km/s)で、これを下回ることはできません。
東京大阪間は直線距離で400km、新幹線のような経路では500kmとなり、
500/300000 = 0.0001666..
往復で約0.33msとなります。
地球一周だと、40075kmで
40075/300000 = 0.1334833..
約133msとなります。
120BPMで16分音符が125msですが、これより少し長いです。
今回16msの遅れということで、波形ソフトで16msずらしたBassDrumとHiHatの音をならしましたが、気にならないレベルでした。
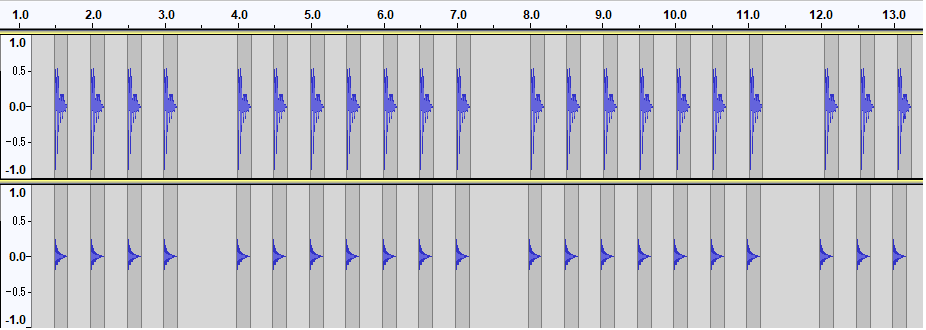
※ジャスト、16ms、30ms、60ms のズレを7回ずつ再生しています。
(どこまで許容できるでしょうか・・楽器によりかなり感じ方が変わりそうです)
さずかにドラムの音の32分音符のズレ(120BPMで62.5ms)は気になりますが、30msくらいまでは問題ないレベルだと思います。
また映像で言えば、60fpsで1フレームが約16msになります。同時の次のフレームには間に合っているということですから全く問題ないです。
ここまで画像や音声のエンコードの時間は入っていませんが、現在のプロセッサで並列処理をしてしまえば極限まで速くできることは想像できます。特に画像は並列処理がしやすいのでいくらでも帯域が許されるかぎり高画質にできるます。
ただ、地球規模では、遅延の少ない演奏は難しいといえます。
しかしモニターするのをエコーバックのみに音声にしてしまえば、133msの遅延は半分になり遅延の気にならない演奏ができそうです。イメージとしてはMIDI音源をながいMIDIケーブルを使って演奏したときの遅れみたいな感じです。聴こえ音が遅れるので演奏する人もそれを計算してはやめに演奏します。このあたりの慣れは脳が補正しています。(ドラムパッドのMIDIアウトでサンプラーを鳴らすときの遅れも同様)
MIDIの転送レートは31.25kbpsでシリアル通信なので、同時に10個の鍵盤を押しても順番に信号が送信されるため同時には届きません。これが帯域が狭いほど遅れる原因になります。帯域と遅延の話は、MIDIに例えるとわかりやすいかもしれません。
31250*(16/1000) = 500
16msで500bitつまり62.5byte。1音につきチャンネル、ノート、ペロシティの3バイトなので、16msで約21 音処理できます。
単純に言えば2人の鍵盤奏者が同時に1つのキーボードを10本の指でノートオンした場合(連弾のイメージ)、最初の音と最後の音では16msずれることになります。
アナログシンセ(CV-Gate)のレスポンスが速く感じるのは、データでなく電圧制御だからでしょう。(ケーブル内を電子が移動するから?押し出す感じ?)

動画で、16msの遅れを3mくらい離れた人に音がとどく時間とありますが、これは厳には音速は15℃で340m/sですので、5.44mになります。
「Sound Lag」
こちらの投稿で音の遅れについて書きましたが、野外での演奏を考えれば、34mで0.1秒くらい平気なので、気にしなくても良いレベルかもしれませんね。
最近はzoomやteamsなどを使ったオンライン会議が盛んになってきたため、リモートで会話する機会が増えました。会話レベルならいいのですが、まだ音を合わせるほどには至っていません。しかし音楽教室などの一方的な演奏であれば、音質などの面で実用レベルにきています。最近GoogleMeet(遅延は比較的少ないと感じている)で打ち合わせのような音合わせをしましたが、コミュニケーションが問題なくできるレベルでした。PCよりもスマホとそのアプリの方がカメラ・マイク、通信デバイスのバランスが良い(と私は思っている)ため遅延が少ないと感じました。ちなみに遅延は往復で500msくらいでした。
テンポの遅い曲で、ピアノ伴奏+弦楽器だったら、100msくらいでもできる気がしますので、もう一息といった感じでしょうか。。
いずれにしろ、遠隔での演奏がどんどん当たり前になってくると、また新たな音楽の楽しみが増えることは間違いなさそうです。
Yukihiro Takahashi / YMO
高橋幸宏氏の訃報から、ネットでYMOの曲を再びよく聴くようになり、昔の記憶が芋づる式によみがえる今日この頃です。
ブログを書くつもりはなかったのですが(やすやすと書けない)、下記の追悼特集を見ていて、何か書きたくなってしまいました。たぶんまともな投稿などかけないので、このタイミングで少しでも記録を残す意味で簡単にまとめてみました。
「Daisy Holiday! 細野晴臣<手作りデイジー>高橋幸宏さん追悼特集 2023.1.22」
https://www.youtube.com/watch?v=i8GOOZdSj_I
「山下達郎のサンデー・ソングブック 極私的・高橋幸宏さん追悼特集 2023.1 .29」
https://www.youtube.com/watch?v=RIvfTpBXPrQ
※上記YouTubeサイトに移動しないと見られません(iframeではNG)
細野さん、教授、ユキヒロ氏と呼ばせていただきますが、この三人そして魅力的なサポートメンバーの才能から生み出された楽曲から、私の音楽人生は多大な影響を受けました。音楽面だけでなくその背景や彼らの接点などからも多く学びました。
ドラマーとしてユキヒロ氏はとにかくフレーズがかっこよく、それが楽曲の一部としてなくてはならない存在感があります。奏法的には、スティックやビーターを打面に押さえつけて叩くタイトな音が特徴的ですが、これは真似できないです。YMO後期にシモンズのエレクトリックドラムを使いだしたとき、これが本来のYMOの音だと、その楽曲のはまり具合に、魅力が倍増したことを思い出しました。シーケンサやパーカッションエフェクトは使っていたものの、初期のYMOはほとんど生演奏で、人力テクノといわれるほどでした。ここから三人のミュージシャンとしての技量の高さがうかがえます。
細野さん、教授の才能がユキヒロ氏のフィルタを通ることによって、ポップになり商業的な成功を収めたという見方もありますが、私もそう思います。ドラム、作曲、歌、ファッションと多才で、本当のアーティストと呼べるのはこういう人のことでしょう。
これ以上、どう書いていいのかわからないので、私のお気に入りの曲を二つ紹介して終わりにします。好きな曲ばかりで選ぶのは難しいのですが、やはりドラムがかっこいいものにしました。
カムフラージュはサンプリングパーカッション、邂逅はオーバーダブしているシモンズが秀逸です。
(YouTube検索でヒットしたものです)
「カムフラージュ/BGM」
「Yellow Magic Orchestra Winter Live 1981 – 4 Camouflage」
「邂逅/浮気なぼくら」
「邂逅 – YMO」
夢中にしてくれた幸せの時間、本当にありがとうございました。
3月5日追記
(練習不足でスミマセン、パターンの繰り返しがきつい。。40年以上前の楽曲とは思えない新しさ。ライブでは演奏されていない曲だが、どうやった叩こうかと思わせる曲。)
4月8日追記
2023 MY EVENTS
今年は演奏する機会が増えそうです。
3月にはコロナ禍などで中断していたバンド活動を4年ぶりに再開し、そのライブがあります。
熱帯JAZZ楽団「MACHETE」のドラムを叩く予定なのでV-Drumsで演奏してみました。(↓動画 なせか音声がまたモノラルになっている・・)
V-Drumsを購入してもうすぐ2年くらいになりますが、これのおかげで練習が楽しくなりました。長らくドラムをやっていますが、アコースティックのドラムセット(生ドラム)を叩いて練習できた時間は数パーセントに満たないくらいです。これまでの多くの時間は練習パッドがメインでした。そう考えると、いろいろな楽器を習ってきましたが、生ドラムは練習の方法についてちょっと特殊な楽器になるかもしれません。
バンド以外にも、バイオリンとジャズベース(コントラバス)の発表会があります。
いろいろな楽器をやっているという実感はなく、演奏したい曲を見つけた後演奏する楽器が決まるという感じです。楽曲と格闘しながら修得していくプロセスに楽しみを感じることを最近気づきました。
発表会演奏曲
2023 ContraBass チャーリー・パーカー「コンファメーション」
2023 Violin シークレット・ガーデン「Song From a Secret Garden」
2022 Cello 坂本龍一「1919」
2021 Violin アストル・ピアソラ「リベルタンゴ」
2020 Cello ジョン・ウィリアムズ「シンドラーのリスト」
2019 Violin 葉加瀬太郎「情熱大陸」
2018 Cello フレデリック・ショパン「別れの曲」
その他余興
2022 Violin MISIA「アイノカタチ」
2021 Cello ケルティック・ウーマン「You Raise Me Up」
弦楽器の練習するときに感じるのは、音量が控えめなので自宅で練習しやすいのと、ピッチ合わせが難しく、デリケートなので、一音一音に集中力がかなり必要になります。そのため頭の中から雑念が消えるというか、他事を忘れることができるためとてもリフレッシュできます。一時期は打ち込みの音楽しか聴かない時期がありましたが、生身の人間が毎回違う演奏することが面白いと思うようになり、それ以来演奏を楽しんています。ドラムはスポーツ感覚というかダンスに近いものがあり、元気がでますね。
新しい年のはじめに元気に叩いてみました。
それから余談ですが、音楽以外にも興味があることが増えています。最近よく思うのですが、人類史上経験のない膨大な情報に一般ピーポーがアクセスできる時代ということです。YouTube一つとってもエンターテインメントから教育、趣味に関することなどさまざまな情報が無限にあり、人々の好奇心を刺激しつづけています。
これまで高度な教育を受けていないと得られなかったり、高い書籍や授業料が必要だったコンテンツが無料動画でしかも検索して即入手できることは驚異的です。(難解な理論も動画での説明がわかりやすいので理解が進みます)
このような状況に、年齢とともに体力面では衰えはあるかもしれませんが、脳は成長しつづけている感じがします。80代でプログラムを学びはじめiPhoneアプリ開発者である若宮さんが少し前に話題となりましたが、年齢とともに衰えると考えるのは、間違いですね。逆にこれまでの経験が増幅されるためよりパワフルになれます。さらに進んでメタバースでアバターを使うことがさかんになれば、国籍も年齢も性別も関係なくコミュニケーションできます。今でもテレワークによるオンライン会議をしているとこのような未来がすぐそこまで来ていることを感じます。
今年は、これまで3Dグラフィクス、AI、ロボット、そして昨年のブロックチェーンにつづき量子コンピュータの記事もブログに書いていきたいと思っています。
https://decode.red/
(音楽に関してはドラム奏法の拡張性がテーマ)
Negative Harmony
Jacob CollierがYouTubeで広めて有名になった音楽理論(オリジナルは古い)で、私も調べてみました。
5度圏を左右に割ってそれぞれの音を交換可とするものです。
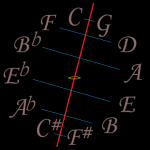
ネガティブということはポジティブに対するものであり、この交換により明るいメジャースケールはマイナースケールに変換されます。
ちょうど陰と陽、夜と昼、月と太陽のような関係に似ているでしょう。この話題にタイミングよく今週11月8日は、442年ぶりとなる皆既月食+天王星食が見られました。

このような天体ショーは、天がときどき人類が宇宙の一部であることを教えるがごとく巡ってきます。きなくさい世界情勢の中、ちっぽけな自分たちの存在を謙虚にうけとめたいものです。
私も観測にいき天体望遠鏡のファインダーからですがiPhoneのレンズをくっつけて、思ったよりきれいに写真をとることができました。今回天気も良く長時間にわたって観測できたため、長く楽しむことができたのではないでしょうか。
他の惑星も見ることができ、土星の環、木星は衛星までも観測できました。
話が脱線しましたが、ネガティブハーモニーの仕組みを図示しました。

このように書くと、一見同主音単調の借用和音のようにも見えますが(モードチェンジしただけ?)、C-G, D-Fの変換が面白いと思いました。
また下記動画でJacob本人のインタビューをもとにしたわかりやすい解説があります。
ここに出てきたスーパーリディアンなるものの説明にも興味を持ちました。
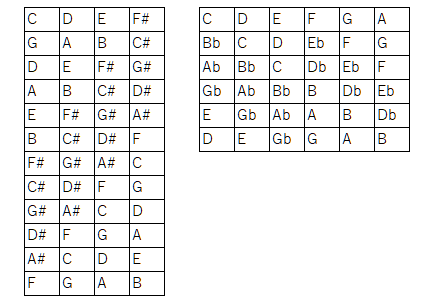
リディアンスケールを左図のようなルールでつなげていくもの(5度圏の#側(陽))と、ミクソリディアンスケールを右図のようなルールでつなげていくもの(5度圏のb側(陰))で、オクターブをまたいで変化していく様子が興味深いです。
ネガティブハーモニーのケーデンスは、V-I から IV-I 変化しますが、このとき
Fm7 -> Bb7 -> Cmaj7
というバックドアケーデンスというものが現れます。動画でもこの用語が使われていますが、初めて知りました。
フロントドアもあるのか、ということで調べてみると、
Bm7-5 -> E7 -> Cmaj7
とありましたが、ネーミングは定かではなさそうです。
https://www.thejazzpianosite.com/jazz-piano-lessons/jazz-reharmonization/ii-v-substitution/
このような周期的な音列を演奏するとき、どんどん転調するためピアノのような鍵盤楽器ではなかなか困難なので、これもタイミングよく最近マイブームである転調しても同じ運指が使えるクロマティックキーボードを使える環境を整えてみました。
下記プログラムを改造して、PCキーボードのクロマティックキーに見立てたコードをMIDI出力できるようにしました。
もともとボタン式クロマティックアコーディオンに興味があり、いろいろと調べていたのですが、高価であるためなかなか手がでずにいました。しかしキーボードだけは体験してみたいと思いPCキーボードを使ってクロマティック演奏を試みました。配列はB-SystemとC-Systemがあるようですが(上下が逆)、C-Systemの方がよく使われているときいたことと、RolandのV-Accordionが採用しているということで、こちらにしました。
実物とは程遠いですが、思った通りこの配列を使うとこれまでと違った感覚を味わえます。(和音の形が視覚的にわかる)
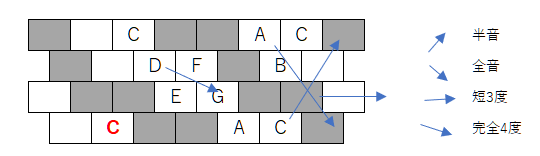
せっかくなので現在勉強中のまとめとして、3タイプの指の形を図示します。音階をひくときにテトラコードを意識すると、横スライドするとき、縦移動で上下にキーが切れたときにフレーズをつなげやすいのかと思っています。
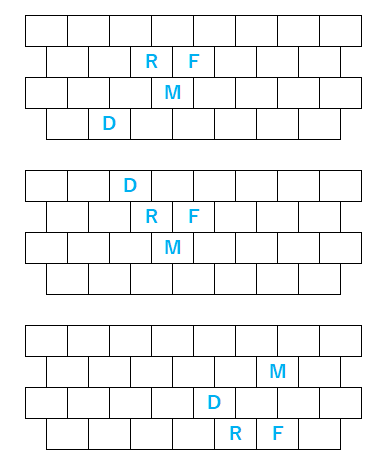
ネガティブハーモニーの話題に戻って考えると、横方向の移動は短3度なので、C->Eb つまり C->Cm となり転調がしやすく親和性が高いです。(Cの1つ左からスタートするAマイナーのスケールをそのままの形で右に1つシフトします。”Chromatic Keyboard”動画の最初の部分)
また交換する音は点対象(天体ショー?)として表せます。
音楽はいろいろな見方ができるから面白いですね、
ネガティブハーモニーを知ったときに思ったのは、光の色を周波数で見る見方と三原色で見る見方の違いに似ているような気がしました。
また整数比から音階を発明したピタゴラスが、宇宙と音楽はともに調和(ハーモニー)がとれて奏でているとし「天球の音楽」といったことを思い返しました。
恵まれた天気で皆既月食を観測できたのも、世界に調和を、という天の声かもしれません。
いろいろな話が盛り沢山になってしまいましたが、このブログらしい展開に自己満足しています。(^^)
※ドレミ表記のもともとのアイディアは以下
iPhone Apps
7月にApple Developer Program に復帰してから、過去のiPhoneアプリを2つ(MusicaMarkerは6年ぶり, TropfMusikは12年ぶり)アップデートしました。
iPhoneアプリの開発は発売当時からやっていますが、途中中断をはさんで3度目の開始となります。
“MusicaMarker”は、ライブラリにある曲の任意の場所をワンタッチ呼び出しができるアプリで、曲を繰り返し聴く必要がある楽器練習のときや、語学の勉強に便利です。”TropfMusik”はこのBlogの最初の方でも紹介しました、Matrix Sequencerです。
ふりかえってみると、開発のきっかけとなったのは、最初にアメリカで発売されたときちょうど仕事で在住していて、同僚が持ってたものを見せてもらったり、いきなりJailBreakのやり方を教えてもらったりして興味を持ったことからです。この頃、SONYのPalmOSやSHARPのLinux Saurusのようなモバイル端末の開発もやっていましたが、その違いに衝撃を受けました。
印象的だったのは、今となっては当たり前ですが、写真のピンチイン/アウトやローテート、なめらかな動き(とくに慣性をシミュレートしたスクロール)をするI/Fです。Apple製品は本当に時代を先取りしているのを感じます。Macが発売されたときもそうでしたが、フロッピーディスクが自動イジェクトするなど、未来のコンピュータという感じでワクワクしました。
帰国してから日本でも発売され、開発を初め、6年前までで、20タイトル以上をリリースしました。売れる売れないに関係なく音楽をテーマにしたアプリで自分が欲しいというのも作って楽しんでいました。ちょうどこのブログもそういった気持ちでやっているのと同じです。(YouTube動画のアップロードももともとiPhoneアプリデモを見せるのがきっかけ。だからipsound。そういう意味では初心に戻ったことに。)
iPadが発売されたときは、グランドオープンと同時にアプリリリースしました。
しかしその後ユーザサポートや、バージョンアップにともなう開発機材のコストが負担になることもあって中断しましたが、Swift言語の登場とこれを使った案件をいただいたことをきっかけに一時再開しました。その後縁がなかったのですが、Apple Siliconへの歴史的転換やAR,AIの機能をみて、参入のタイミングをはかっていましたが、ようやく最近環境が整い再々開しました。
Developer Program に復帰してから、AppleStoreには、過去のアプリを出現するようになってしまいましたが、動作しないもの、強制的に削除されたものがあり、混乱状態にあります。
基本的に最近アップデートし動作確認したのは、いまのところ下記2タイトルだけです。(“Perfect Pitch Practice Piano”は動作確認済)
https://apps.apple.com/app/id1082130243
https://apps.apple.com/app/id369685150
Demo動画(short movie はembededできない?)
https://youtube.com/shorts/1OaWi2Ijpd0
https://youtube.com/shorts/Hjk6riZAbQg
CPUが32bit(iPhone5まで)から64bitに変更されたことにより、特に私のサウンド関連のアプリは大幅な変更をする必要がありました。今後数タイトルを復帰させ、それから新規のアプリも作っていきたいと思っています。(2016年のSwift言語で開発したアプリはiPhoneによっては動作するかもしれません)
過去アプリの情報は、
http://iphone-old.iiv.jp
まだ移行中で一時的なWebサイトは、
http://iphone.iiv.jp
です。
Breath of Groove
今回もドラムマガジンの誌上ドラム・コンテストにチャレンジしました。
春は「SUPER INSPIRATION」という32小節の小曲でしたが、夏はいつもどおりです。前回(春)のときテンポを倍にしたアプローチがカッコよかったので、今回まねしてみました。
歌ものということでBreath(息、呼吸)という言葉が使われたと思いますが、息継ぎができないくらいハードなプレイとなってしまいました。(笑)
反省) 動画の音声のLチャンネルが無音になってしまった。(接触不良? iPhoneのスピーカで聴いてアップロードしたのでわからなかった。 どうしよう・・)
あと、Rolandの100人セッションの曲の動画がとても楽しそうだったので、叩いてみました。
https://blog.roland.jp/event/playerssummit2022_100ss/
反省) ハイハットが回ってしまい、センサがない部分になると音がならない・・
結局、前のブログと合わせて本日だけで3つの動画を収録することとなりました。(まるでミッションをこなすかのごとく) ドラム三昧の一日に、ちょっと息ぎれ。
Ryū kyū Scale
琉球音階は、ド・ミ・ファ・ソ・シ からなる5音音階で、たっだ5音を奏でただけで琉球の音楽とわかる強力なアイデンティティを持っています。
テンポが速い曲も遅い曲も底抜けに明るい印象があります。
今回このスケールをガイドにドラムを叩いてみました。
反省) 動画の最後のURLが間違っている。jpがjoに・・orz、次になにやるか迷い手がおおい。
きっかけとなったのは先月TBSで放送された「音楽の日」にモンゴル800が演奏した「琉球愛歌」を聴いたことでした。「小さな恋のうた」はカラオケで歌ったことがあり知っていたのですが、この曲は初めて聴いて、そのリズムの多彩さに圧倒されました。歌詞とメロディとリズム全てで訴えかける、すごいパワーを感じました。いろんな音楽がありますが、その人の人生とか感情とか音楽で伝わるものなのだと実感しました。この曲の歌詞は今の時代考えさせられます。歌詞つきのいい動画がありましたので、貼り付けました。
https://www.youtube.com/watch?v=6aIsc2uYDZs
モンゴル800の曲は他の曲もそうなのですが、リズムのテンポが倍になったり半分になったり、間が独特だったりと、曲がドラマチックに展開します。人もそれぞれ違うリズムを持っていますが、どんなリズムも受け入れる寛容さ、スケールの大きさを感じました。
Sound Lag
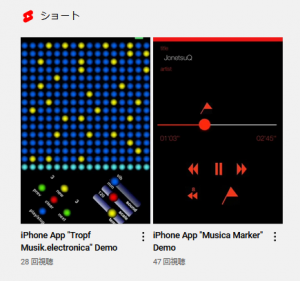
野外などの広い場所で楽器を演奏していると音ズレが気になることがよくあります。それは音が進む速度(音速)が意外と遅いからです。
気温に影響を受けるため、その関係をRの関数でグラフにしてみました。
参考)WiKiPedia
https://ja.wikipedia.org/wiki/%E9%9F%B3%E9%80%9F
一般的に15℃で秒速340mとしているようです。
340mというと34mで0.1秒ずれることになり、マーチングバンドの演技フロアが30m x 30m ということを考えるとその影響は大きいです。(120BPMで16分音符が0.125秒)大編成のパレードなどではさらに大きなずれが生じます。
ずれないようにするため、指揮者を複数人置いたり、練習ではメトロノームを複数台使ったりするようです。(フロアなら有線のスピーカ、野外だとFMトランスミッタで送信して携帯ラジオで受信など、試したことがあります)
過去にiPhoneアプリで同期メトロノームを販売したこともありました。
(12年前の懐かしの動画です。こういうのを残してくれているとこがYouTubeのいいところですね)
また音ズレに関して言えば、ネットを使ったセッションでもいえます。音声のエンコード・デコード、データ送受信のバッファリングのしくみを考えれば、かならずレイテンシーは存在します。ところが人間の能力でそれをある程度カバーすることが可能であることを、ユーチューバのかてぃん氏の動画で見たことがあります。自分の演奏(のフィードバック)が少し遅れて聴こえることを許容すると、遅延を半分にできるということです。
簡単に言えば遅れることを前提にセッションするということでしょうか。
他にも音ズレというのは、勘違いを引き起こすことがあります。
今月はじめ参議院選挙期間中に安倍元首相が凶弾に倒れました。許しがたい犯罪で社会全体が暗い気持ちになりました。こういうとき社会が冷静になるためには正しい情報を知る努力をする必要があると思っています。銃撃されたシーンの動画がネットに上がっていますが、その一つが2度目の銃撃の前に襟元が動くことから、容疑者以外が狙撃したという指摘がされています。その動画(動画A)には容疑者が映っていないため、発射のタイミングが特定できないことと、煙のタイミングより後に発砲音がなっていることから、容疑者が映っている別の動画(動画B)と重ねて見てみました。動画Bは襟元が識別できませんので、iMovieで動画Aのピクチャーインピクチャーで見た目を合わせ同じタイミングで同時に再生されるようにしました。すると動画Aの音声トラックが0.2秒ほど遅れており、襟元の動きは容疑者の銃撃によるもののように見えます。
しかし動画Aには襟元の動きと同時になっているヒュンという鞭が空を切るような音が入っているのですが、これが狙撃の音だという指摘があります。(動画Bでいえばさらに0.2秒前になる)
この空を切る音と2度目の銃撃音の間には0.28秒ほどの時間差があります。銃弾は音速を超えるので、爆発音より早く聞こえるのは問題ないような気がしますが、0.28は長すぎるように感じました。気温を30とすると音速350m/sくらいで 350 x 0.28 = 98mです。98m離れていないとこの時間差を感じられない、ということになるからです。(そうするとこの音は容疑者の銃撃とは無関係ということになります)
そもそも弾丸の飛ぶ音かどうか、音速を超えたときのソニックブーム(衝撃波)が聞こえるタイミングだとか、弾丸の正確なスピードだとか、こういうに詳しくないとだめですね。
https://sun-tv.co.jp/suntvnews/news/2020/06/12/25120/
前々回の選挙のこともそうですが、タイトルからは飛躍した内容になってしまいました。そういえば以前もSoundCloudの話題で、ショパンコンクールの話題を取り上げたりしましたから、こういうBlogだと思えばいいのか、と開き直りました。
なにより発信、OUTPUTが大事と思っています。
昔の動画はまだユーチューバーという言葉がない時代、容量の大きい動画ファイルの置き場程度のことでYouTubeを使っていましたが、今は随分とその役割がかわったことを改めて思いました。
iPhoneアプリまた作りたくなってきた・・
Volca Drum Jam
前回、慣れない外でのプレイで集中できなかったので、今回は室内で遊んでみました。
Korg NTS-1をエフェクタとして使っています。もともとこれはシンセのオシレータをプログラミングできる強力な音源で、おもちゃみたいな外見からは想像がつかないすごいマシンです。(音もかなりいい)
以前、2opのFM音源を作っていますが、エフェクトもプログラムできます。
https://decode.red/blog/202103271271/
前回、撮影した日が名古屋駅ロータリのモニュメント「飛翔」が撤去される直前だったと後で気づいて、動画を残しておけてよかったと思いました。(そういえば以前BeatStopCameraのデモをとったときも、大名古屋ビルヂング撤去の前でした)
Korg Volca Drumは連続的に変化する物理モデル音源の音色の幅が広くとても気にいっています。その分デリケートでかなり操作が難しいです。爆裂な音を作るのは簡単なのですが、それをカッコよく聞かせるのにはまだまだスキルが足らないです。以前にお気に入りのBastl Kastle DrumもJamっていますが、これも同様です。シンセ的サウンドとパーカション的サウンドをいったりきたりするとこが好物なのですが、今そのあたりを研究している(楽しんでいる)段階です。
あと関係ないですが、最近ささった動画です。
「林修×チームラボ代表・猪子寿之★斬新なデジタルアートで世界を魅了!世界基準の仕事術とは!? 」
フリーランスとして働いているのになんで、と言われそうですが、それゆえに勝つためには、やはり団体戦で戦うべきといつも感じています。音楽にも言えますが、私がいろんな楽器を習っているのもアンサンブルが楽しいからです。動画の最後に「自分にとって意味があればなんと言われても関係ない」とありますが、短期的な成果を求めるのではなく長期的な展望をもって動くためには、とても必要なメンタルだと思います。
Volca Drum In The Open Air
YouTubeではVolcaシリーズなどの小型シンセ(BASTLなどもよくみかける)を野外でプレイする動画がよくあり、自分もVolcaシリーズを一度外に持ち出して動画をとってみたいとずっと思ってました。
ちょっと前に購入したVolca Drumが音の表現の幅が広く、単体でも十分に面白いことができることから、これを持ち出してみました。場所は名古屋駅前のロータリーで、前もBeatStopCameraというiPhoneアプリのデモ動画でとったことがあります。
また今回、ちょうど参議院選挙期間中ということで思うところがありました。
さまざまな情報から日本の弱体化はよく知られていますが、これまで我々が謳歌してきた資本主義社会のルールでは基本的にお金を持っている人たちが社会を思い通りに動かすことができます。
ということは資本主義のルールで負けるということはどういうことか。。最近よく考えます。
政治とか宗教とかの話題はいろんな場面で避けられることが多く、話題となるのは事件だったり不祥事があったりするときだけですが、YouTubeとかみていると、政治とは全く関係のないチャンネルが今回の参議院議員選挙の街頭演説をアップロードしているのを見ました。
良い社会、良い未来を希望するのであれば、やはり政治に無関与ではいけないと思い、カジュアルに私も今回とても気になった政党を取り上げてみました。政党要件をまだ満たしていないため、党員が7万人もいるのもかかわらず諸派という扱いということもあり、新聞・TVメディアの露出は少なくあまり認知されていません。(メディアの報じないことはないことになる) 改めてメディアの影響力について考えさせられます。(詳しくはYouTube動画説明欄)
初めてということで、操作でブレたりするところや、演出がいまいちなのは反省点としてありますが、メタリック基調の構造物に、Volca Drumって結構あうものだと感じました。
やりたい形はできましたが、このマシンの良さを引き出しておらず、繰り返しみると残念の気持ちに・・
(なかなかムズい)
Super Inspiration
2022年のドラムマガジンの誌上ドラム・コンテストは、春と夏の二回あるようです。
そのためか従来の3分くらいの曲ではなく、32小節という短い曲”Super Inspiration”になったようで,今回も応募しようと動画を作成しました。
動画をアップロードしてから他の人の動画を見て毎回思いますが、それぞれのアプローチの仕方がユニークでとても勉強になります。
(この曲テンポを倍に解釈すればいいんだ。気づかなかった・・とか)
こういうコンテストがないと、自分の好みの曲ばかり叩いたり、わざわざ動画も作成しないことから、参加する意義はまさにここにあります。
ドラムコンテストきっかけで独自の動画も作るモチベーションとなり、今回第一弾としてArturia Micro FreakとのJamセッションをやってみました。もともとこちらが目的でしたが、コンテストが早まったため(例年は8月ごろ)、Jamセッションのキットのまま撮影しました。このためMicroFreakとかそのままです。
せっかくなのでパーカションの音を一つ使いました。
Jamの方は、こんなことやりたいという形を実現しましたが、まだまだです。(とりあえずアウトプット!)
機材)
Roland V-Drums TD-17
Roland TD-7(今回使わず)
TAMA Speed Cobra 310
Auturia MicoFreak
Audius Streaming Platform
前回、OpenSeaに画像をアップロードすることによりNFTについて考えました。今回は音楽を扱うプラットホーム Audius を試してみました。AudiusはOpenSeaで扱うEthereumやMaticと同じ暗号通貨という分野ではあるのですが、音楽のNFTではありません。同じデジタルデータとはいえ画像と音楽が同じNFTとして扱われることにまだ違和感があります。Audiusはこのブログでもよく使っているSoundCloundに変わるものになるのではないかと言われ、サービスも充実してきていることから、NFTではなくFTの暗号通貨という側面もあることから試してみました。
Audiusについて
https://fisco.jp/media/audius-about/
アップロードした曲は以前SoundCanvasのバックアップのための動画から選択しました。
https://audius.co/keip/sc88pdemo

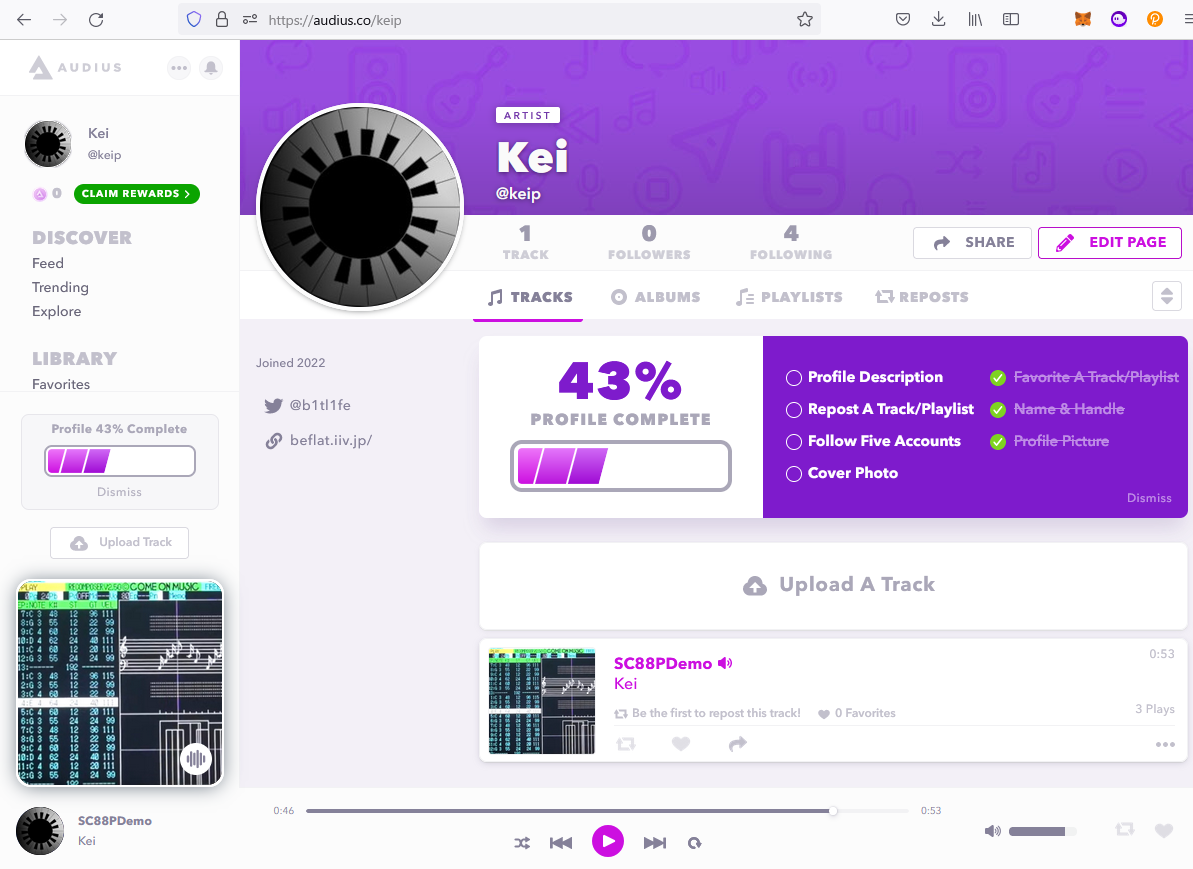
これまでのサービスと違うところは、音楽をアップロードしたりと曲を聴いたりするなど、さまざまイベントをこなすと暗号通貨$AUDIOで報酬を受け取れるということです。(請求していない今はゼロです)
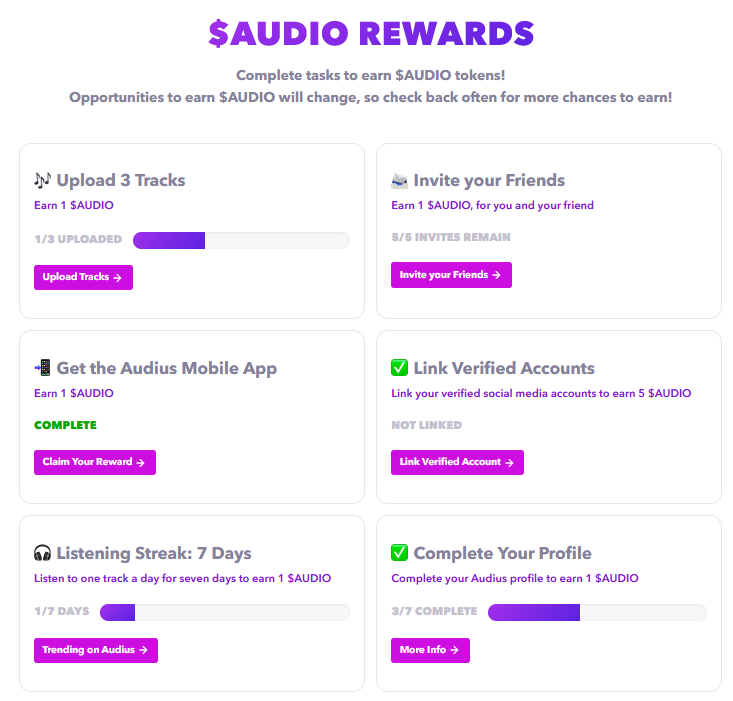
暗号通貨を使ってアーティストが稼ぐしくみを作ったことはとても画期的だと思います。
では、1 Audioはどのくらいの価値があるかというと、最新のCoinMarketCapのチャートでは、
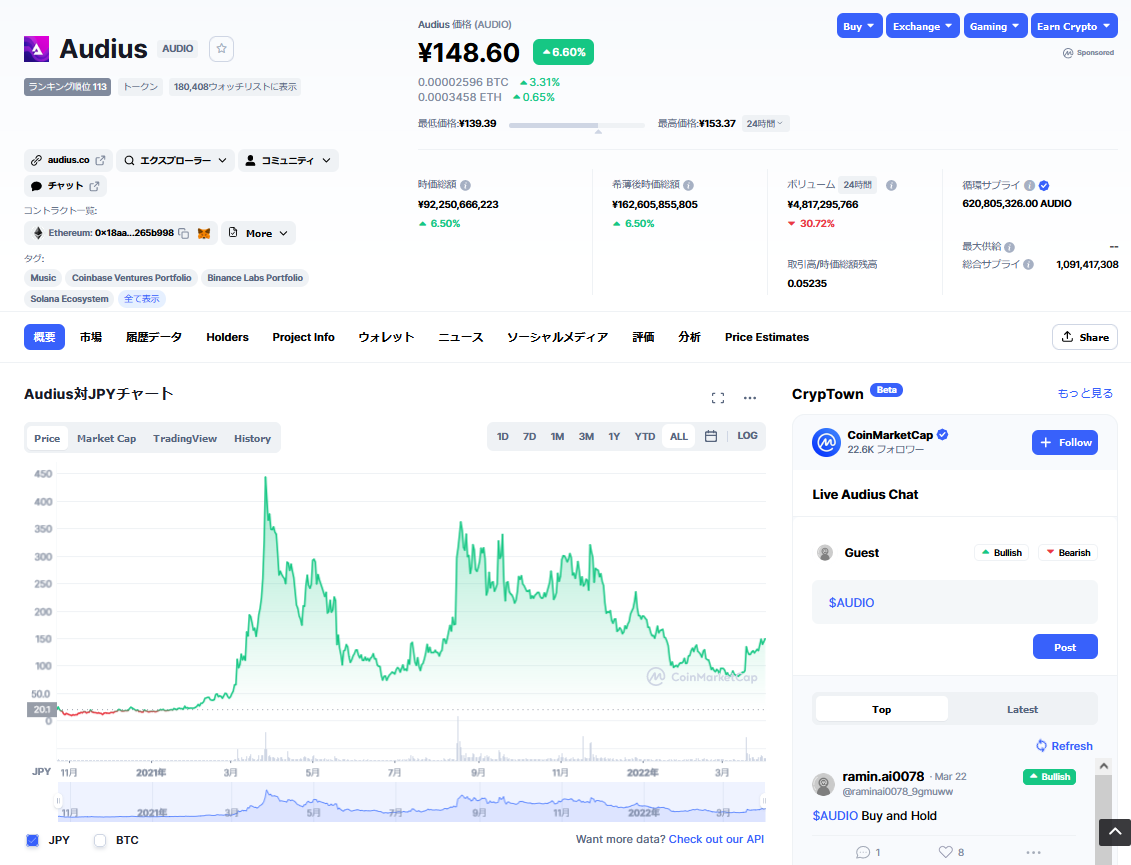
148円でした。これが多いか少ないかは人それぞれですが、リアリティがあります。
(暗号通貨なので買うことも売って換金することもできますが、手順はちょっと複雑なのとこのブログの意図ではないので省略します)
NFT化して流通とか可能になれば、また面白そうです。Web3時代のデジタルコンテンツはいろんな組み合わせで楽しみ方が増えると予想しています。(これまで考えられなかったものが組み合わさる可能性がある)
今一番興味があるのがブロックチェーンテクノロジですが、起きているイベントが多すぎてキャッチアップできていないと感じています。新しいアイディアを生み出すためにも、ついていく必要がありますが、このAudiusもその一つになります。
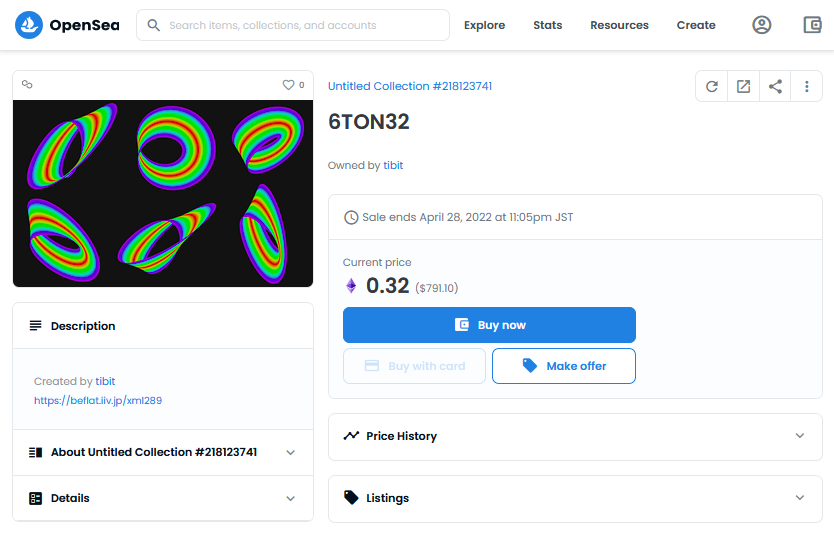
Open Sea : NFT
今話題のデジタルデータの所有権を証明できるブロックチェーンのコントラクト、NFT(Non-Fungible Token:非代替性トークン)の最大マーケットであるOpenSeaに将来の著作権に関することの勉強を目的に下記投稿の動画に使ったオリジナル画像をサンプルで出品してみました。(動画も出品できるのですが、今主流なのは静止画だろうと思いました)
音楽を扱っているマーケットもあるのですが、アーティストが限られているなど手軽にできるものが見当たりませんでした。近い将来もっと自由に出品できるマーケットができたり、SoundCloudのようなサイトが対応するのではないかと期待しています。

ここからここに至った背景を書こうと思いますが、かなり専門的な用語が多くなります。備忘録として残しておきたいのでご容赦ください。
(OpenSeaやメタマスクの使用方法はYouTubeなどに詳しい説明がありますので、検索してご覧ください)
ビットコインにはじまるブロックチェーン技術の発展により、さまざまな暗号資産(クリプトカレンシー)が生まれ、そのトレードがとても盛り上がっています。個人的にトレードには興味があまりなかったのですが、NFTの出現により、アートや音楽の未来を変える可能性を感じ深く理解したくなりました。
NFTというのはビットコインの次にでてきたコインのやりとり(ERC-20)だけでなく契約の記録(ERC-721)ができるイーサリアムのコントラクトの一つです。(OpenSeaは正確に言えば両者二つの合わせたERC-1155) デジタルデータが本物かどうか、だれが所有してきたかの履歴を証明できます。
NFTの技術的なテストはこちら。
https://decode.red/net/archives/904
ただブロックチェーンというデータをP2Pネットワークで維持するので、動画のような膨大なデータはどのように保存するのだろうという疑問かあり上記でテストしました。データ本体はブロックチェーンに記録されねわけではなく別のネットワーク(ipfsなどはP2P)に保存して、そのハッシュ値をブロックチェーンに記録ようです。そうするとデータ自体が紛失した場合はどうなるのだろうという疑問が生まれましたが、そもそもそれは想定していないのかもしれません。ブロックチェーンだってノードを立てるインテンティブがなくなれば消滅するからなのでしょう。
OpenSeaというのはイーサリアムネットワークのサービス(ビットコインネットワークではない)ですので、ETHコインを使います。ところがこのネットワークがガス代(ブロックチェーンに登録するための手数料)がかなり高く、今まで敬遠していました。ところが手数料の安い(登録・リスティングまで無料だった)ポリゴンネットワークからも利用できることがわかり、試してみることになりました。
ただ実際に購入する人がもしいるとすれば、イーサとポリゴンのブリッジをするサービスを使ってコインを移動する必要があります。(ポリゴンネットワークのネイティブコインはMATICですが、OpenSeaではETHを使う。しかし登録時にポリゴンネットワークを選んだ場合、メタマスクにMATICがないとエラーになる。額は0でもいいみたい。登録の次に販売するのにリスティングするがそのときは不要・・だと思う)
OpenSeaの登録に先立ち、OpenSeaの登録とは関係ないですが(やらなくてもよい)、ウォレットアドレスのネーミングサービスENSにtwitterで使っている名前tibitを登録しました。(インターネットのIPアドレスをドメインネームを登録するようなもの)
このようなことをしたのは、ドメインネームフェチなのもあるのですが、クリプトをトレード以外で使いたかったからです。メタマスクとばれる拡張機能がブラウザにインストールされていると、支払が必要になるとたちあがり課金が簡単にできます。これはアマゾンなどで商品を買うのとはまた違った感覚です。とはいっても手数料が高すぎるし、一度ガス代不足で登録に失敗したためその分の手数料もかかってかなりの出費でした。つまりブロックチェーンの改竄がきかないしくみというのは、やり直しがきかないことなのでそのあたりの緊張感はあります。(tibit.ethという名前をウォレットに入れると私に簡単に送金できてしまいます^^)
今回NFTきっかけでブロックチェーンを深く理解しようとしましたが、いろいろ調べていると国家、社会システムへの影響が半端でないということを感じました。ITに関して長くかかわってきたのである程度自身があった自分ですが、この技術に関してかなりリテラシーがないことを気づかされました。
メタマスクのようなブロックチェーンを利用したアプリケーションはDapp(Decentralized Application:分散型アプリケーション)と呼ばれますが、現在はこのようなウォレットや両替、ギャンブルを中心として金融関連のものが多くしめます。NFTが出現してアイテムで利用するゲームが増えてきましたが、まだまだ物足りない気がしています。もっとアートに関して便利で面白いアプリはないかといろいろと考えています。そのためブロックチェーンを理解するためのブログも作りました。

Algodoo & Volca FM
2Dの物理シミュレーションを楽しめるAlgodooというソフトがありますが、MIDIを出力できるようにしてKorg Volca FMをならしてみました。
MIDIプログラムとAlgodooシーンの説明はそれぞれ以下のものを使用
「Rust MIDI library」
「Algodoo プログラミング (3)」
https://decode.red/ed/archives/1112
音だけだとただのランダムな音がなっているだけですが、音の出るプロセスが見えると違って聴こえるのではないか、という実験です。音源は、E.PianoでDecayTimeを少し伸ばしています。
ここではほとんどが固定されたシンプルな例ですが、もう少し動きのある物体を使ったシーンするなど、まだまだ考えていきたいです。
Sound Cloud
このBlogを始めたころは実験的な音源をよく上げてしていたのですが、久しぶりにSoundCloudに新作(というほどのものでもないですが)をアップロードしました。
SoundCloudはYouTubeと同様、SNSの機能もありますが、私の使い方はBlogがベースでそのコンテンツ置き場になっています。(最近SoundCloudのコメントにBlogのURLを記載しました。自分でも探さないとわからなかったため・・)
音楽を純粋に(映像とかなしに)音だけで、聴くことができるプラットホームを利用するのは、音だけで表現できる作品を作りたい、という憧れからです。映像や説明付きであったりライブであったりする方が面白いという音楽も好きですが、音のみの作品は、自分の中の First Placeです。まだ一般的に聴いてもらえる代物ではないですが、自分が後から聴くときにいろいろ感じることが次へのステップに役に立つことがあるので有意義です。
ピアノ演奏をアルゴリズムとドラム演奏で、チャレンジした”Behind the Piano 01″というものを作ったことがあります。私はピアノを弾くことはできないので憧れの楽器であり、とても興味深い対象になります。楽器自体とても機械的で合理的なもので、弦楽器や管楽器に比べて単音の表現力が乏しい側面を持っていますが、その合理性の賜物として一人でオーケストラ級の音楽を表現することができるほどの能力を持っています。オーケストラというものは基本的に単音楽器(弦楽器の重音などは無視)を大人数で演奏されますが、人間の「個」というものを(「個」というもので)表現することには不向きです。ピアノでは高度に訓練された身体によりそれが表現できることがとても魅力です。(コントロールできる情報量が多い)
“Behind the …” を製作プロセスや演奏の様子が見ることのできない音のみとして(Blogでは説明していますが)、SoundCloudを利用するのは一番の理想形だからです。
PIanoについて熱く語ったのにPianoとは関係ないですが、今回の新作(いい響き)も、このような意図からアップロードしてみました。
最後にこのようなネットサービスで思うことろですが、使用しないとアカウントが凍結されたり、提供会社が買収されたりしてサービス停止したり、またある理由でコンテンツが削除されたりなど永続的に存在が保証されていないことが、リスクとしてあります。Blogやドメインなども利用料を支払い忘れたら消滅する可能があります。またプログラムのアルゴリズムや製作・開発環境などもPCのOSやアプリが古くなったりすると再現できないとか、装置の故障などでデータを紛失したりとか、どうしてもデジタル時代のリスクは避けられません。デジタルコンテンツは部分的にでも、音声データや動画データとして分散しておくといいでしょう。(このBlogの初期にもう動作しなくなった私のiPhoneアプリなどの動画を紹介したときも同様なことをかきましたが・・)最近話題のブロックチェーンで実現するNFT(非代替性トークン)などはそういった問題も解決するかもしれません。
[追記 2021/10/21]
第18回ショパン国際ピアノコンクールで2位反田恭平さん、4位小林愛実さん日本人で二人入賞しました。なんとYouTubeで予選から見ることができるので応援していました。反田さんのファイナルの演奏を見て、もしかして初の1位がとれるのではと期待していたのでちょっと悔しいですが、素晴らしい結果だと思います。YouTuberのかてぃんこと角野さんも3次予選(ファイナル直前)まで進み、いつもテレビやネットでおなじみの人たちの活躍にとても楽しみました。
その他にも日本人が結構このコンテストに参加していることに驚きました。いろんな演奏を聴いてあらためて音楽の楽しいだけでない厳しい側面を感じました。私はそれぞれの選曲の個性がでる3次予選がとても興味深かったです。1時間に近い間、聴く人を飽きさせず、ミスせず、集中して演奏する姿を見ていると、この人たちは幼い頃からどれだけの鍛錬を積んできたのだろうと感心するしかありませんでした。
話はがらっと変わって19日にAppleが新しいMacBookを発表しました。今回の新製品はブレイクスルーとなる素晴らしいものです。 動画を見ているとこれからのクリエイターの向かう方向みたいなものを感じ取ることができました。テクノロジーでかなりのことができてしまう、これは今までもそうですが、テクノロジーが関与していく部分というものも見えてきた気がしました。かなりはしゃりますが、テクノロジーは人間の生活を便利にしますが、鍛錬をしなくてもいいということではない、ということです。AIの時代、人間の個性という身体性がより重要になってくるでしょう。ピアノコンクールはあと100年たっても続いているような気がします。なぜそのような感じるのか、生身の身体の可能性を追求したい、と思うからかもしれません。
最近の日本の政治や経済の話でよく思うことは、過去の栄光や資産によって守りに入っていないか、楽をしようとしていないか、何かに頼りすぎていないか、などです。もっと個々人が鍛錬しないといけない、と感じます。
アルゴリズムとドラミングで多くの情報を操作した音楽表現をしてみたいと思っているものとして、そのための理論つくりや肉体的な鍛錬を、ストイックなピアニストに学び、続けていく励みにしたいと思います。
https://en.wikipedia.org/wiki/XVIII_International_Chopin_Piano_Competition
より
Brand Model Serial number
S1 Steinway & Sons D-274 611479
S2 Steinway & Sons D-274 612300
Y Yamaha CFX 6524400
F Fazioli F278 2782230
K Kawai Shigeru EX 2718001
カワイピアノも健闘!
Kastle Drum & V-Drums JAM
ドラムシンセモジュールのBastl Kastle Drum と Roland V-Drumsで遊んでみました。(前からやってみたかった・・)
Kastle Drum は、前にも使ったM5Stackによるコントロールをしました。これにより揺らぎを作り出すことができます。Kastleの制御はデジタルなのですが、インターフェイスとなっているのはアナログ電圧なので、どこか不安定に感じる部分があります。逆にこれが人が合わせる場合、しっくりくる感じに思えます。
今回はこれを改造して振幅をボタンで変化できるようにしました。
演奏の途中でいろいろと音を変えながら柔軟にプレイしようとしましたが、Kastle自体目的の音にするのが難しく(つまみのわずかな差で音が全く変わる)、まだまだ修行が必要です。
(1カメでサイズ差がありすぎる二つを同時撮ったためおかしな構図になってしまいしたが、そのうち撮り方も考えないと・・)
M5から電圧で制御しているのは、DECAYとPITCHですが、バターンとかもやれないかと思っています。アナログI/F、いいですね。
MILESTONE
今回もリズム&ドラムマガジンコンテスト(第20回誌上ドラム・コンテスト「MILESTONE」)に応募しました。
毎年自身が真剣にプレイすることで、他の人の動画の曲の解釈とかプレイスタイルをより理解でき、とても刺激になります。今年は、東京オリンピックの競技期間中に練習していたこともあり、ちょっとアスリート気分になりました。偶然にも曲名「トライアルロード」が、とてもマッチしています。
実際、課題(曲)をどのように攻略するかとかはスポーツクライミング、演技・構成を組み立てるところなど新体操などに似ています。スケートボートなどの新競技の躍動的なパフォーマンスやeスポーツが将来競技に入る可能性とかを考えると、そのうちドラムとかも競技になるのじゃないかと、妄想していました。
打楽器は楽器の中で体全体を使うことからスポーツに近く、古今東西どの国にもあり、いろんな種目ができそうです。
こうなると圧倒的にアメリカが強そうですね。(WGI(パーカッションのみのマーチングバンドの大会)とか見にいくとそう思います。駐車場も会場も全員がドラマー)
住宅事情から日本はドラマーには不利な環境ですが、最近はRolandの電子ドラムV-Drumsの性能が上がってきたためこれを克服しつつあります。年少者のドラマーの活躍がめざましいのも、こういったものが影響しているのではと思います。
という私も今回V-Drumsでチャレンジです。コストパフォーマンスがいいTD-17を使用しました。(これまで所有していたTD-7から大幅なグレードアップ)生ドラムと比べると、メッシュヘッドのタッチの違和感はありますが、モニタリングがしやすいというメリットは大きかったです。
フェンシングの突きや水泳の着順の判定をタッチセンサでするなど、人の目では判定できないものの電子化は進んでいます。ドラムが競技になった場合は、たぶん電子ドラムが使われるでしょう。(また妄想)
妄想はさておき、異例ずくめの東京オリンピックでしたが、それゆえいろんなことを感じました。
開閉会式は、さまざまな影響から随分と予定が変更され、リオ五輪閉会式の演出の延長を期待していた自分としては、ちょっと残念でしたが、パラリンピックの開会式、テーマ”WE HAVE WINGS”は、本当に素晴らしいショウでした。
新型コロナ拡大の中の、オリンピック開催の賛否について、ちょっと前に「ファクトフルネス」という本が話題になりましたが、ここに書かれていることがたくさん当てはまることに驚きました。(悪いニュースの方が圧倒的に耳に入りやすい、といったネガティブ本能)
バイアスのかかった報道が、世論をミスリードする様子が顕在化したのではないでしょうか。
複雑になる世の中、多変数の連立方程式を解くような問題が今後も増えるでしよう。扱いやすい変数だけ見た議論は一見わかりやすいが、これでは問題を解けないため、ファクト(客観的なデータ)をもとに状況を見極める力が必要だと強く感じました。
オリンピック参加前と後で国が変わってしまうようなことが起こるというの世の中、今日まで合法だったものが明日から違法になる全体主義、クーデター、政権転覆、を見ていると国とは何なのか考えさせられます。このような時代だからこそ、オリンピックのような国境を越えた人類共通の価値、ルールのプラットホームというのは必要性が増していると思います。音楽も同様の力をもってますね。
アコースティックドラムの代替えとして、エレクトリック(電子)ドラムを使用しましたが、練習で叩いていてエレドラならではの音楽の可能性も新たに感じることができました。(特に生ドラムのリアルさがなくても可) いろんなJAMで使っていきたいと思っています。
今回は自分の音楽ライフにとって一つのマイルストーンになりそうです。(うまくまとめたつもり・・)
収録時メモ)
ドラム: Roland V-Drums TD-17
ペダル類: TAMA Speed Cobra 310 (BD, HH)
※iPhoneで曲を再生しながら、TD-17でドラム音のみSDカード録音
iPhoneとTD-17をBlutetooh接続で収録したところ、ステレオミックス時にづれることが判明。(ワイアレスの不安定が原因か)
iPhoneとTD-17をライン接続に変更。
※今回審査員に若いころから影響をうけた神保氏がおられるということで、イントロは一番好きな曲「ミッドマンハッタン」からオマージュです。
Table Top Music
Desk Top Music(DTM)というと机の上でPCを使って音楽を作るというスタイルを意味しますが(DeskTop Publishing:机で印刷物の作成するDTPもよく似た意味)、テーブルトップという言葉も最近はよく聴くようになりました。
ビートボクサーで有名なBoss RC-505といったルーパーを使った音楽もそのように言われることがありますが、私の解釈としてはDTMよりもよりカジュアルなものを指すのではないかと思っています。
ここ最近Korg Volcaシリーズを中心としたJAMをしてきましたが、ちょっと表現の幅を広げたくなりARTURIA MicroFreakとRoland TB-303クローンのBehringer TD-3に手を出しました。
TD-3は唯一無二の303ベースシンセサウンドで、無条件で大好きなサウンドです。MicoFreakはたくさんのシンセサイザの要素と機能が凝縮されていて、音つくりがとても楽しいマシンです。両者ともかなりパンチ力があります。
実はプログラマでありながら、音楽だけは昔からマウスを使ってシーケンサを使うスタイルが好きになれず、シーケンサ付きシンセが最近安価になってきたこれらのマシンは、自分にとってとてもフィットものになります。各シーケンサ(MicroFreakはLFO)をもちろん同期させるのですが、そ以外は自由にフレーズをStart/Stopさせて、尺も適当に遊ぶのがとても楽しいです。
ドラム&パーカッションはVolcaSample2を使いました。同期のマスターになっています。(接続はVolca->MicroFreak->TD-3の順)
303のディストーションがかかったベースは何やってもカッコイイですね。ちょっとプレイは控えめにしています。
実際は、Volcaのときもそうですが、カメラスタンドがいつも邪魔でプレイしにくいため、つまり撮影時は控えめにならざるを得ない状況になっています。
今はいろいろと試している段階ですが、そのうちカメラとかのセッティングやクォリティもきちんとしたいと思っています。
VCV Rack Jam
別件でソフトウェアモジュラーシンセを使ったとき、フリーでは基本モジュールしか使えないと思っていたのですが、ユーザ登録するだけでかなりのモジュールを使えることがわかりました。
https://vcvrack.com/
ということで早速いろんなモジュールを試してみましたが、数が多すぎてそれぞれ何ができるのか把握するのにかなり大変だということがわかりました。(嬉しい悲鳴)

大きな分類としてHardware Cloneと呼ばれるハードウェアとして存在するもののソフトウェアシンセとソフトウェアならではの自由な発想のものと別れます。
まずはHardware Cloneを中心にいろいろと調べてみました。実際の製品を試すことなくどんな音がでるのか十分に知ることができ、高価なものゆえ気にいったものをじっくり検討して購入する動機に十分になると思いました。ソフトだけで十分楽しめますがマウス操作では一つのつまみしか操作できないのと、実物の音圧にはかなわないでしょう。
次のステップは、何のモジュールか理解した後これで音作りすることですが、これはかなり難しいです。文字通り思考錯誤しながら私も作ってみました。
テーマとしては、ステップシーケンサの単調さをできるだけ回避できるように、多様な変化を起こすことです。
ピッチの周期とエフェクトの周期をづらすとか、フレーズがワンパターンかされてきたら、クロックでトリガーされる数を少なくして雰囲気を変えたりするなど、試しました。
左上のINSTRUOのモジュールは、前に購入したKastle Drumとルックスもだけでなく音も似たところがあります。アルゴリズムとかオープンソースになっていてそういったものを利用することもよくあるようなので、今はやりの音なのかもしれません。
憧れだったモジューラシンセで、このようなことが簡単にできてしまう今の時代にあらためて驚きます。
音作りの面では既になんでもできる時代は来ているのですが、モジュラーシンセという自由度を組み合わせるというのは究極的なものだと思います。
この次にはいったい何がくるのでしょうか・・
Volca FM + Volca Sample2
FM音源といえばYAMAHAのデジタルシンセサイザのDXシリーズですが、DX7ともSysexでデータ互換があるVolcaFMは手軽に高品質なFMサウンドを体験できる製品です。

DX7は音色のエディットをボタンとボリュームスライダで行う、操作もデジタルでしたが、VolcaFMではアナログライクのつまみで操作できる(MIDIコントロールの可)ことが気に入りました。
それからVolcaシリーズならではの個性的なステップシーケンサとアルペジオレータが魅力です。
今回テストしたかったのは、このシーケンサとアルペジオレータをピッチ制御しながらシームレスに使えるように外部MIDIコントロールすることです。MIDIプログラミングにはMAXを使いました。
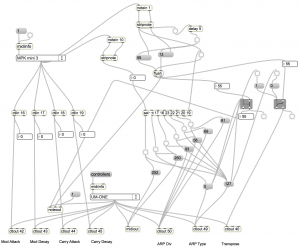
主に、AKAIのMIDIコントローラMPKのMIDI信号をVolcaのコントロールチェンジに変換する役割をしています。ビッチ制御ではノートオンのホールドができるようにしています。
あとシーケンサのStart/Stopなどもコントロールして、アクティブステップシーケンスの操作以外、MPKでできるように試みました。
せっかくなのでVolca Sample2も使って同期しました。
またDEXEDというソフトシンセのデータを転送することもできることから、音色データの作成がしやすくなっています。FM音源はたくさんのパラメータがあり、これを有効に制御することはとても難しいのですが、これを手軽にできるしくみをこのVolca FMは持っています。
あと3台欲し〜です。
BASTL Kastle Drum
チェコのBastl Instrumentsという会社のDIY電子楽器、Kastle Drumを手にいれました。
輸入品ということもあり、ちょっと割高感がありましたが、このサイズでモジュラーシンセということにとても惹かれました。一つ前のKastle v1.5 という製品も欲しかったのですが、もう一つ決め手がなく、しかし今回これを”Drum”と言うことの非凡性と、Volca Modularを補完する(一緒に使いたい)部分を持っていることで試したくなりました。

なぜDrumというか、それはグリッチ(Glitch)サウンドをリズムパターンで演奏するからです。汚れ音系は以前から興味があり(ちょっと前に流行ったサーキットベンディングなど・・)、一つ間違うとバグなのですが、その微妙なさじ加減を調節するのにはセンスがいります。Volca Modularで物足りないと思ったのがノイズだったので、この二つはとても相性がいいと思いました。 トリガーにつかうパルス(ステップシーケンサ)のパターンはあらかじめ決まっていますが、電圧によって音色のゾーンを変えられるので、パターンが変化しているように聞こえます。NOSE,CLOCK,LFO,Patternの出力がそれぞれ3つあるのですが、バリエーションを出力すると思いきや、残念ながら同じ信号を出力しているようです。
Kastle Drumは狙いの音にするのがとても難しく、頭を整理するためにも独立した外部から変調ソースを使っていろいろとテストしました。
LFOが一種類でしかもクロックと同期しているので、モジュレーション対象がパターンの周期と一致するようになっています。これはどんな状態になってもリズムパターンと認識させるための狙いだと思いますが、ずらしたいときもあります。こういうときは外部のLFOを使って実現します。(このデモの詳細は下記ブログに記述)
アート集団がたちあげた会社だけにノイズにもセンスがあります。
もちろんモノフォニックシンセなので、同時発音数が1ですが、ノイズのリニアドラミングのようにも聴こえます。これもDrumという所以なのか。
この2機種によって、モジュラーシンセの音作りの自由と面白さを新たにしました。KORGさんにはVolca Modularの後継機を期待しつつ、今回モジュラーシンセのバッチケーブルのかわりに、M5Stack(Arduino)のGPIOをジャンバーで接続するという発想に出会うことになって、自分でも作れそうな気がしてきました。
https://decode.red/blog/202102111259/
http://bitlife.me/em/2021/02/12/kastle-drum/
 D5 Creation
D5 Creation